
스프링을 학습하다보니 if문이나 다른 반복문을 많이 써야 하는 경우, Stream과 람다식으로 대체하면 쉽고 깔끔한 코드가 되는 경우를 많이 보았다.
아직 사용에 익숙하지 않아 Stream 기능에 대해 정리해보려 한다.
- 예시
1
2
3
4
5
public Member login(String loginId, String password) {
return memberRepository.findByLoginId(loginId)
.filter(m -> m.getPassword().equals(password))
.orElse(null);
}
이러한 코드를 람다식을 사용하지 않고 표현한다면?
1
2
3
4
5
6
7
8
9
public Member login(String loginId, String password) {
Optional<Member> findMemberOptional = memberRepository.findByLoginId(loginId)
Member member = findMemberOptioanl.get();
if (member.getPassword().equals(password)) {
return member;
} else {
return null;
}
}
람다식을 사용하면 작동방식이 이와 같다고 보면 된다.
- 참고
1
2
3
4
5
6
7
//memberRepository
public Optional<Member> findByLoginId(String loginId) {
return findAll().stream()
.filter(m -> m.getLoginId().equals(loginId))
.findFirst();
}
findAll은 Member가 들어있는 List를 반환한다. 얘도 스트림과 람다식 사용전으로 돌려보자.
1
2
3
4
5
6
7
8
9
public Optional<Member> findByLoginId(String loginId) {
List<Member> all = findAll();
for (Member m : all) {
if (m.getLoginId().equals(loginId)) {
return Optional.of(m);
}
}
return Optional.empty();
}
filter()가 내부에서 stream을 순회하면서 맞는 조건에 해당하는 것을 찾는다는 것을 어렴풋이 알 수 있다.
Optional
Null일수도, 아닐수도 있는 Object를 담은 객체이다.
1
2
3
public static <T> Optional<T> of(T value);
public static <T> Optional<T> empty();
public static <T> Optional<T> ofNullable(T value);
- of() : Null이 아닌 오브젝트를 이용해 Optional을 만들 때 이용한다. 인자로 Null을 넘길 시 에러가 발생한다.
- empty() : 빈 Optional을 만들 때 사용한다. = Null
- ofNullable() : Null인지 아닌지 모를 오브젝트로 Optional을 만들 때 사용한다.
of() 같은 경우는 저기에 쓸 수 있다면 개발자가 Null일 가능성이 없다고 판단한 것인데 의미가 있나 싶을 수 있다.
하지만 개발자가 의도치 않은 동작으로 Null이 발생할 수 있고 그것을 대처하기 위한 도구라고 보면 된다.
스트림?
람다를 활용해 배열과 컬렉션을 함수형으로 간단하게 처리할 수 있는 기술.
기존의 for문과 Iterator를 사용하면 코드가 길어지고 가독성과 재사용성이 떨어지며, 데이터 타입마다 다른 방식으로 다뤄야하는 불편함이 있다.
스트림은 데이터 소스를 추상화하고, 데이터를 다루는데 자주 사용되는 메서드를 정의해놓아 데이터 소스에 관계없이 모두 같은 방식으로 다룰 수 있으므로 코드의 재사용성이 높아진다.
특징
- 원본 데이터 소스를 변경하지 않는다. 읽기만 한다.
- 일회용이다. 한번 사용하면 닫혀 재사용이 불가능하다.
- 최종 연산 전까지 중간 연산을 수행하지 않는다.
- 작업을 내부 반복으로 처리한다.
- 병렬처리가 쉽다.
- Collection은 외부반복이고, Stream은 내부반복이다.
- 기본형 스트림을 제공한다.
1
2
3
Stream<Integer> 대신 IntStream-기본형스트림을 제공하여 오토박싱과 언박싱 등의
불필요한 과정이 생략되고 숫자의 경우 유용한 메서드를 추가로 제공한다.
ex) .sum(), .average() 등등
외부 반복 vs 내부 반복
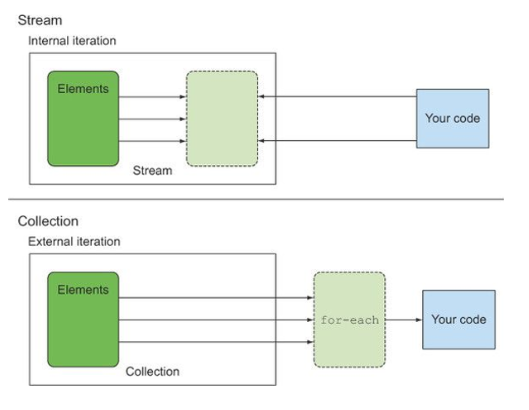
내부 반복은 작업을 병렬 처리하며 최적화된 순서로 처리해준다.
외부 반복은 명시적으로 컬렉션 항목을 하나씩 가져와 처리해야한다. Collection에서 병렬성을 이용하려면 직접 synchronized를 통해 관리해야 한다.
참고
스트림 사용
선언
1
2
3
4
5
Stream<T> Collection.stream()
Arrays.stream(arr)
list.stream()
Stream.of('value', 'value' ... )
forEach()
1
list.stream().forEach(System.out::println);
지정된 작업을 스트림의 모든 요소에 대해 수행한다. 위의 코드로 보면 모든 요소에 대해 출력하는 것이다. 반환 타입이 void이므로 스트림의 요소를 출력하는 용도로 많이 사용된다.
stream은 한번 사용하면 닫히기 때문에 forEach를 두 번 호출할 수는 없다.
distinct(), filter()
1
2
Stream<T> distinct()
Stream<T> filter(Predicate<? super T> predicate)
1
list.stream().distinct().forEach(System.out::println);
1
2
3
list.stream().filter(x -> x%2 == 0).forEach(System.out::println);
list.stream().filter(x -> x%2 == 0 && x%3 != 0).
list.stream().filter(x -> x%2 == 0).filter(x -> x%3 != 0).
- distinct() : 스트림에서 중복된 요소 제거
- filter() : 주어진 조건에 맞지 않는 요소를 제거
sorted()
1
2
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
1
2
list.stream().sorted()
list.stream().sorted((a,b) -> b-a)
스트림을 정렬하기 위한 메서드이다.
map(), boxed(), collect()
map()
1
Stream<R> map(Function<? super T>, ? extends R> mapper
1
2
3
4
5
6
7
8
9
10
fileStream.map(File::getName)
.filter(s -> s.indexOf('.') != -1)
.map(s -> s.substring(s.indexOf('.') + 1)
.map(String::toUpperCase)
.distinct()
.forEach(System.out::println);
Stream<String> stream = list.stream()
.map(String::toUpperCase); //[A,B,C]
.map(Integers::parseInt); //문자열을 정수로 전환
스트림의 요소에 저장된 값 중 원하는 필드만 뽑아내거나 특정 형태로 변환해야 할 때 사용한다.
mapToInt(), mapToDouble(), mapToObj(), boxed()
map()이 Stream 타입의 스트림을 반환하는데, 아래의 mapToInt(), mapToLong(), mapToDouble() 과 같은 메서드들은 기본형 스트림으로 반환한다. -> IntStream, LongStream..
1
2
3
student.stream().mapToInt(Student::getTotalScore)
arrList.stream().mapToInt(x->x).toArray(); //ArrayList 배열 변환
arrList.stream().mapToInt(Integer::intValue).toArray();
- 기본 스트림은 추가적인 메서드를 더 지원해준다는 장점이 있다.
- 기존의 map()을 사용하면 count()만 지원해주는데 기본형 스트림은 sum(), average(), max(), min() 등 숫자를 다루는데 편리한 메서드를 제공해준다.
반대로 기본형 스트림을 스트림으로 변환할 때는 아래와 같이 사용한다.
1
2
3
4
Stream<U> mapToObj(IntFunction<? extends U> mapper
// 기본형 스트림을 Stream<T>로 변환할 때
Stream<Integer> boxed()
//기본형 스트림을 Stream<Integer> 과 같이 변환할 때
- boxed() : 예를 들면 int 자체로는 Collection에 담을 수 없기 때문에 Integer 클래스로 바꾸어 주어 List에 담는 등의 작업을 할 때 이용한다.
1
2
3
int[] num = {3,4,5};
Arrays.stream(num).boxed().collect(Collectors.toList());
collect()
- Stream의 아이템들을 List 또는 Set 자료형으로 변환할 때 사용한다.
- Stream의 아이템들의 평균값을 리턴
- Stream의 아이템들을 Sorting하여 가장 큰 객체 리턴
- 등등..
1
2
3
4
5
6
7
8
String[] str_arr = {"banana", "kiwi", "apple"};
stream().collect(Collectors.joining(", "));
//banana kiwi apple => String으로 변환
stream().collect(Collectors.joining());
//bananakiwiapple
stream().collect(Collectors.toSet());
//set으로.
** String이라 boxed() 없이 바로 된 것이지 만약 int 배열에 적용했다면 toSet() 과 같은 작업을 할 때는 boxed()를 사용해 기본형 스트림에서 바꾸어주어야 한다.
joining()은 char, String에 적용한다.
sum(), average(), max(), min()
1
2
3
4
5
6
7
8
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
int[] arr = {1,2,3,4,5};
Arrays.stream(arr).sum();
list.stream().mapToInt(x -> x).sum();
list.stream().mapToInt(x -> x).average();
list.stream().mapToInt(x -> x).max();
list.stream().mapToInt(x -> x).min();
위에서 설명했듯이 기본형 스트림에만 제공된다. 따라서 mapToInt를 해주었다.
이 때 sum()을 제외하고는 반환형이 특이하다.
- sum() : int
- average() : OptionalDouble
- max() : OptionalInt
- min() : OptionalInt
OptionalInt ?
Optional 객체와 같은 원리이다. 애초에 Optional 객체에서 파생된 것이다.
다만 값을 가져올 때 방식이 조금 다르다.
1
2
3
4
5
6
7
//일반적인 Optional
Optional<Integer> i = Optional.of(1);
System.out.println(i.get());
//OptionalInt
OptionalInt b = list.stream().mapToInt(x->x).max();
int x = b.getAsInt();
- Optional : get()
- OptionalInt : getAsInt();
- OptionalDouble : getAsDouble();
- OptionalLong : getAsLong();
allMatch(), anyMatch(), noneMatch()
스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는 지, 일부가 일치하는 지 등등의 연산을 한다.
1
2
3
boolean allMatch(Predicate<? super T> perdicate)
boolean anyMatch(Predicate<? super T> perdicate)
boolean noneMatch(Predicate<? super T> perdicate)
1
2
3
4
5
6
7
List<Student> students = Arrays.asList(new Student("lee", 10),
new Student("hong", 14),
new Student("kim", 16));
boolean match = students.stream().allMatch(s -> s.num < 15); //false
boolean match = students.stream().anyMatch(s -> s.num < 15); //true
boolean match = students.stream().noneMatch(s -> s.num < 9); //true
findFirst(), findAny()
스트림의 요소 중 조건에 일치하는 첫 번째 것을 반환하는 findFirst(). 주로 filter()와 함께 사용되어 조건에 맞는 스트림의 요소가 있는지 확인하는데 사용된다. 병렬 스트림인 경우 findAny()를 사용해야 한다.
1
2
3
4
5
Optional<Student> student1 = students.stream().filter(s -> s.num == 10).findFirst();
Student student2 = students.stream().filter(s-> s.num == 10)
.findFirst()
.orElse(null);
기본 반환은 Optional이다. 스트림의 요소가 없을 때는 비어있는 Optional 객체를 반환한다.
groupingBy(), partitioningBy()
1
2
3
4
5
6
Collector groupingBy(Function classifier)
Collector groupingBy(Function classifier, Collector downstream)
Collector groupingBy(Function classifier, Supplier mapFactory, Collector downstream)
Collector partioningBy(Predicate predicate)
Collector prationingBy(Predicate predicate, Collector downstream)
collect() 와 함께 쓰이며 그룹화와 분할에 사용한다.
그룹화는 스트림의 요소를 특정 기준으로 그룹을 만드는 것을 의미한다. 분할은 스트림의 요소를 두 가지, 즉 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로 나누는 것을 의미한다.
예시를 보자.
- partitioningBy()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//Student 객체에는 이름, 남자인지(성별), 학년, 반, 점수가 들어간다고 가정한다.
//1. 기본 분할
Map<Boolean, List<Student>> stuBySex = stuStream.collect(partitioningBy(Student::isMale));
List<Student> maleStudent = stuBySex.get(true);
//2. 기본 분할 + 통계 정보
Map<Boolean, Long> stuNumBySex = stuStream.collect(partitioningBy(Student::isMale), counting());
int male_student = stuNumBySex.get(true); //남학생 수
//3. 복합 사용
Map<Boolean, Optional<Student>> topScoreBySex = stuStream
.collect(partitioningBy(Student::isMale, maxBy(comparingInt(Student::getScore))));
- groupingBy()
1
2
3
4
5
6
7
8
9
10
11
12
Map<Integer, List<Student>> stuByAge = stuStream.collect(groupingBy(Student::getAge));
// ,toList() 생략됨. 생략가능
Map<Integer, List<Student>> stuByAge = stuStream.collect(groupingBy(Student::getAge, toCollection(HashSet::new)));
Map<Student.Level, Long> stuByLevel = stuStream
.collect(groupingBy(s -> {
if(s.getScore() >= 200) return Student.Level.HIGH;
else if(s.getScore() >= 100) return Student.Level.MID;
else return Student.Level.LOW;
}, counting())
//각 레벨별로 학생을 분류하고, 그 분류된 학생의 수만큼 Map의 value로 기록.
스트림 메서드 분류
스트림 메서드들의 종류와 예시는 위에서 다루었고, 메서드들의 분류 기준이 있다.
- 가공 (중간 연산)
- 스트림의 요소들을 가공하는 중간연산이다. 여러 개의 중간 연산이 연결되도록 반환값으로 Stream을 반환한다.
- filter(), distinct(), map(), mapToInt(), boxed() 등등..
- 스트림의 요소들을 가공하는 중간연산이다. 여러 개의 중간 연산이 연결되도록 반환값으로 Stream을 반환한다.
- 최종 연산
- Stream을 바탕으로 결과를 만든다. 최종 연산 이후에는 Stream의 요소를 소모하고 닫기 때문에 더 이상 사용할 수 없다.
- forEach(), count()
- sum(), average(), max(), min()
- allMatch(), anyMatch(), noneMatch(), findAny(), findFirst()
- collect()
- toList(), toSet(), toMap(), toCollection(), toArray()
- counting(), summingInt(), averagingInt(), maxBy(), minBy()
- groupingBy(), partitioningBy()
- Stream을 바탕으로 결과를 만든다. 최종 연산 이후에는 Stream의 요소를 소모하고 닫기 때문에 더 이상 사용할 수 없다.
스트림의 단점
- 디버그가 힘들다.
- 스트림은 한 번에 모든 것이 수행된다. 따라서 에러가 발생하면 스트림을 다시 조립해야 할 수 있다.
- 다른 사람이 스트림 코드를 디버깅하려면 힘들 수 있다.
- 재활용이 불가능하다.
- 스트림의 최종연산이 수행되면 닫히기때문에 한번 정의해놓고 재사용할 수 없다.
마무리
스트림의 메서드를 보면 확실히 편리하게 원하는 기능을 작성할 수 있다. Spring 프로젝트 내에서도 많이 활용할 수 있다.
하지만 메서드들이 많고 처음에는 적응이 필요하다. 사용하면서 어떤 오류를 마주칠지 모르므로 코딩테스트 연습문제 풀이하거나 할때도 적용해보는 등 어느정도 연습이 필요할 것 같다.