
핀포인트
- 네이버에서 만든 APM (Application Performance Management) 도구이다.
- 분산된 애플리케이션의 성능을 모니터링하고 분석하는 용도로 활용된다.
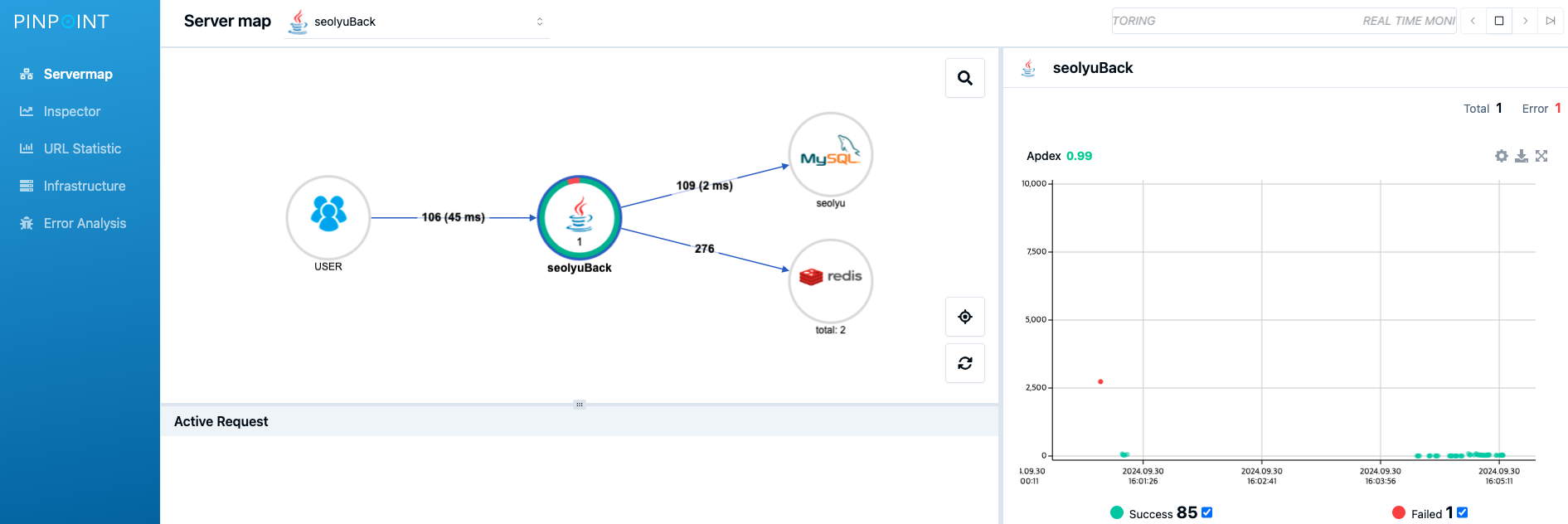
- 실시간으로 애플리케이션의 서버맵, 실시간 활성 쓰레드 차트, 요청/응답 차트, API 호출 상세 기록 등등을 추적하고 문제가 발생하면 그 원인을 쉽게 찾을 수 있도록 해준다.
애플리케이션의 서비스 간 관계를 자동으로 분석해주고 호출 맵을 생성해 아키텍처를 시각화한다. 분산된 시스템에서 특히 장점을 가진다.
분산 트랜잭션을 추적하여 병목, 에러, 느린 쿼리 등을 상세하게 파악할 수 있도록 해준다.
구성 요소
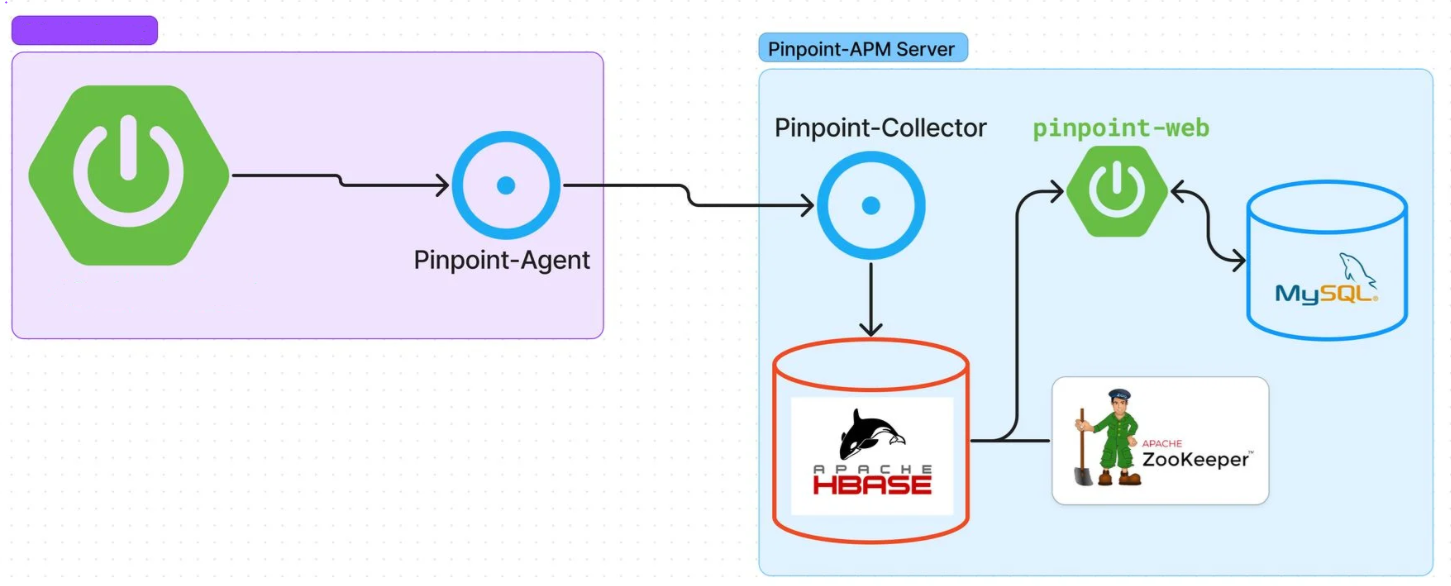
핀포인트는 총 4가지 요소로 구성된다.
- Pinpoint Agent
- 애플리케이션에 설치되어 데이터를 수집하는 역할
- Java 또는 Python 기반의 에이전트이다.
- 메서드 실행 시간, HTTP 호출, DB 쿼리 등의 정보를 수집한다.
- Collector
- 여러 Agent에서 수집한 데이터를 모아 처리하는 서버이다.
- 데이터를 저장소에 저장하고, 사용자 인터페이스로 제공한다.
- Web UI
- 사용자가 모니터링 데이터를 조회할 수 있는, 데이터를 시각화하는 웹 인터페이스이다.
- 성능 그래프, 호출 맵, 트랜잭션 트레이스 등등의 정보를 시각화해 제공한다.
- Storage
- 주로 HBase를 기본으로 사용한다.
- 수집된 성능 데이터를 저장하는 저장소이다.
개발환경에 따라 이 4가지 요소를 설치하는 버전이 달라질 수 있다.
Java 17버전이라면 아래와 같이 설치하는 것을 추천한다고 한다.
- Agent: 3.0.x
- Collector: 3.0.x
- Web: 3.0.x
- HBase: 2.x
Java 버전에 맞는 핀포인트 요소들을 설치하는 것이 중요하다.
장단점
장점
- 설치가 간단하다.
- 기존 애플리케이션 코드의 수정이 필요 없다. Agent만 설치해주면 된다.
- 확장성이 좋다.
- 위에서 설명했듯 분산 환경에서도 장점을 가진다.
직관적으로 성능을 모니터링할 수 있다는 것이 가장 큰 장점이며 Java 기반 대규모 분산 시스템에서 활용도는 더욱 높아진다. 병목현상을 효과적으로 해결 가능하다.
단점
- Java/Python만 지원한다.
- 데이터 저장소에 대한 의존성이 있을 수 있다.
- HBase
핀포인트 로컬에 적용
로컬에 핀포인트 관련 요소들을 직접 설치하지는 않을 것이다.
Agent만 애플리케이션에 등록하고 나머지는 핀포인트에서 도커 환경을 위한 세팅을 잘 해놓았기 때문에 Docker를 이용한다.
단, 로컬환경이기 때문에 HBase 대신 경량화된 저장소를 활용한다. Docker Compose를 이용하면 Lite 모드로 쉽게 설정이 가능하다.
1. Pinpoint Docker Compose 가져오기
1
git clone https://github.com/pinpoint-apm/pinpoint-docker.git
1
cd pinpoint-docker
- Lite 모드 활성화: HBase대신 경량화된 Lite 모드 사용
- docker-compose-latest.yaml 파일을 사용하면 된다.
- 만약 해당 파일이 존재하지 않는다면 docker-compose 파일을 열어 HBase 관련 부분을 제거해주면 된다.
1
docker-compose -f docker-compose-latest.yaml up -d
! docker-compose 파일을 열어보았더니 zookeeper에 관련된 부분이 있었다.
그런데 채팅 시스템에 Kafka를 적용해놓아 로컬에 Zookeeper가 설치/실행이 되어 있었는데, 그 이유로 분리해서 사용하고자 docker-compose의 Zookeeper 부분의 포트를 바꾸어 주었다.
더해 혹시나 로컬의 Redis, MySQL 서버와 충돌할까 싶어 Redis, MySQL 관련 설정도 있어 포트를 각각 1씩 증가시켜 바꾸어주었다.
경우에 따라 다른 서비스의 포트도 바꾸어야 될 수 있을 것 같다.
그리고 pinpoint-quickstart, pinpoint-agent, pinpoint-attach-example 부분은 필요없기 때문에 주석처리 해준다.
1
docker-compose up -d
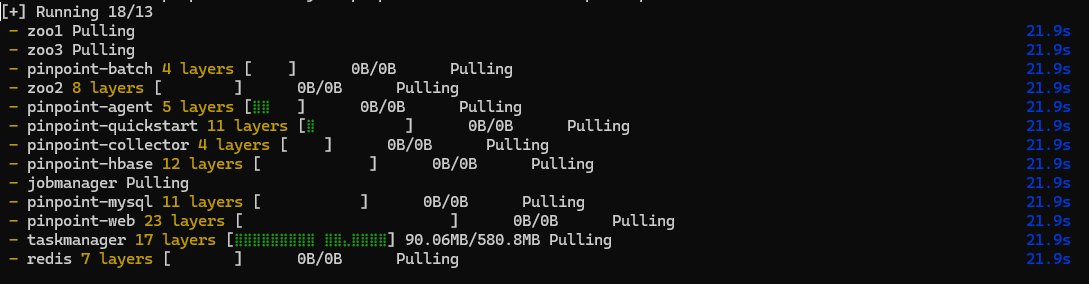
문제점
HBase를 포함해 도커 컨테이너를 다 띄웠더니 CPU와 RAM 사용량이 90% 이상으로 치솟았다.
HBase는 Pinpoint가 수집한 데이터를 저장하고 Zookeeper는 HBase의 동작을 지원하는데, 클러스터 환경에서 동기화를 담당한다고 한다.
일단 이 부분들은 분산 서비스에서 수집한 데이터를 저장할 때 필요한 것이고 로컬에서는 실시간 데이터만 확인하고 분석하면 되기 때문에 HBase와 Zookeeper에 관한 부분을 주석처리하고 다시 실행한다.
–> pinpoint-web이 정상적으로 나타나지 않는다.
리소스 관련 부분은 다른 방법을 찾아봐야 할 것 같다.
작업관리자를 열어보니 Vmmemwsl 프로세스에서 매우 많은 리소스를 소모하고 있는게 문제다.
우선 C:\Users\사용자이름 폴더에 .wslconfig 파일을 생성하고
1
2
3
[wsl2]
memory=5GB
swap=0
이렇게 메모리 크기를 자신이 원하는 만큼 할당해주면 해결이 된다고 한다.
2. Pinpoint Agent 다운로드 및 설정
Pinpoint GitHub Releases에서 최신 버전의 Agent를 다운로드한다.
나는 Java 17을 사용하기 때문에 3.0.x 버전을 다운로드 할 것이다.
- pinpoint-agent-3.0.1.tar.gz를 다운받았다.
- 다운받은 파일을 C드라이브에 압축해제 해주고, pinpoint.config 파일을 설정해줘야 한다.
1
2
3
4
5
6
7
8
9
10
11
# Collector 설정
profiler.collector.ip=127.0.0.1
profiler.collector.tcp.port=9994
profiler.collector.stat.port=9995
profiler.collector.span.port=9996
# 에이전트 정보
profiler.agentId=dangdang
profiler.applicationName=dangdang-salon
profiler.sampling.rate=1
나는 위의 설정들을 해주었다.
- collector.ip = Pinpoint Collector의 IP 주소
- 로컬이기 때문에 127.0.0.1
- agentId = 에이전트의 고유 ID
- 서로 다른 애플리케이션 간 중복되면 안된다.
- applicationName = Pinpoint Web UI에 표시될 애플리케이션의 이름
- sapling.rate
- 기본적으로 주석처리 되어 있는데, 주석을 해제했다.
- 화면에 노출할 예시 결과를 지정한다.
- 20이면 5%의 확률로 값이 노출되어 20번의 요청을 해야 1건의 요청값이 화면에 나타난다는 얘기이다.
- 1이면 모든 값을 화면에 노출시킬 수 있다.
이 외에도 다양한 설정들을 할 수 있다.
설정이 완료됐다면 Pinpoint Agent를 Java 애플리케이션의 JVM 옵션에 추가하여 연결해야 한다.
VM 옵션을 수정해야 한다.
IntelliJ 기준 Run -> Edit Configuration 메뉴로 접근하고 Modify options에서 VM Options를 추가한다.
그리고 아래 내용을 그 부분에 입력한다.
1
2
3
4
5
6
7
-javaagent:C:\PinpointAgent\pinpoint-agent-3.0.1\pinpoint-bootstrap-3.0.1.jar
-Dpinpoint.config=C:/PinpointAgent/pinpoint-agent-3.0.1/pinpoint-root.config
-Dpinpoint.agentId=dangdang
-Dpinpoint.applicationName=dangdang-salon
-Dserver.port=8083 //8080이 기본 -> 충돌로 8083 사용
-XX:+DisableExplicitGC
-XX:+UseG1GC // G1GC 가비지 컬렉션을 사용한다.
- XX: 설정 값들은 가비지 컬렉션 관련 설정이다. 해당 옵션이 아닌 기본값으로 했을 때 지속적인 관련 예외가 발생한다고 한다.
정상적으로 적용됐다면 실행 시 아래와 같은 로그들이 나타난다.
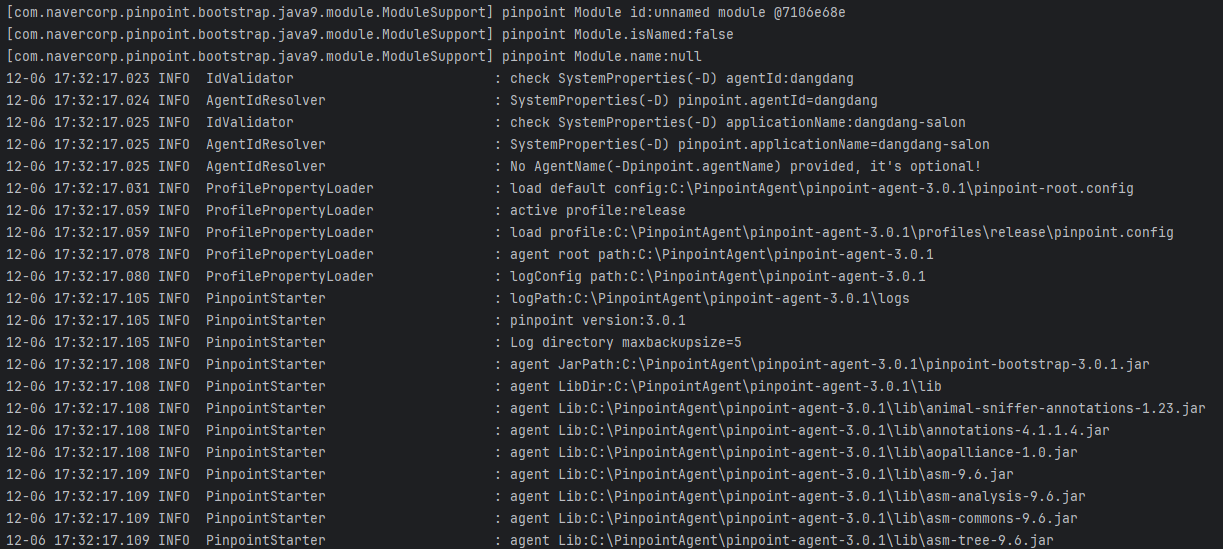
에러
Agent 등록과 Docker-Compose 컨테이너들은 모두 제대로 실행됐다.
1
-- Failed to send agentInfo= ....
이 에러가 나타나면서 애플리케이션의 정보를 Collector가 받지 못하는 현상이 계속 됐다.
1
No meta znode available
Collector의 로그를 보니 이런 문제가 있었고 HBase와 Java 버전 호환성 문제, 설정 파일에서의 문제, 포트 문제, Zookeeper가 제대로 실행되지 않거나 HBase와 통신을 하지 못하는 문제 등등을 의심하고 지속적으로 해결하려고 했으나 결국 실패했다.
그래서 로컬에 설치하지 않고 Naver Cloud 환경에 Collector, HBase, Web을 설치하고 우선 로컬 애플리케이션에 Agent를 연결해 사용해보고자 한다.
Naver Cloud 시작
처음 사용했을 때 3개월 기간 한정 주어지는 크레딧 10만원을 이용해 적용해보려고 한다.
가입하고 페이지 좌측 Services 메뉴에 들어가면 Management 분류에 Pinpoint Cloud라는 메뉴가 존재한다.
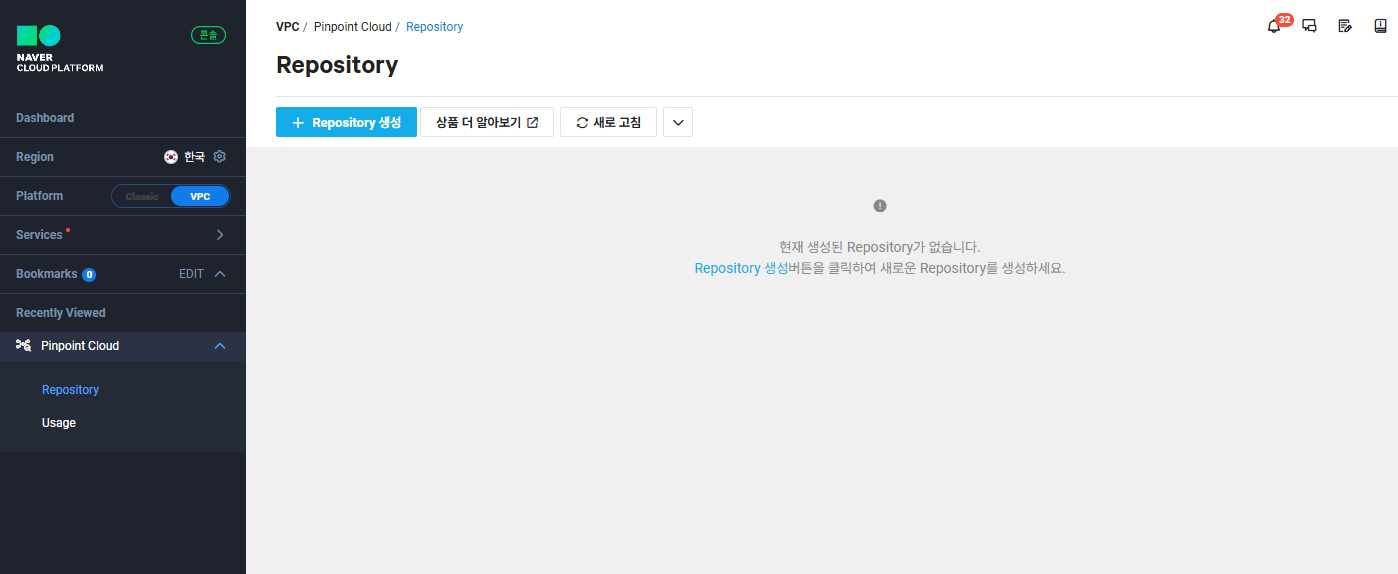
접속하면 위와 같은 화면이 나타나게 되고, Repository 생성을 해주면 된다.
간단한 정보들을 입력하면 Repository가 생성된다.
이후 바로가기를 누르고 Repository를 생성하면서 입력한 Repository 이름, 관리자 ID, Password를 입력해 로그인해주면 된다.
Agent 설정
접속한 화면에서 우측 상단 설정버튼 - Installation 버튼을 누른다.
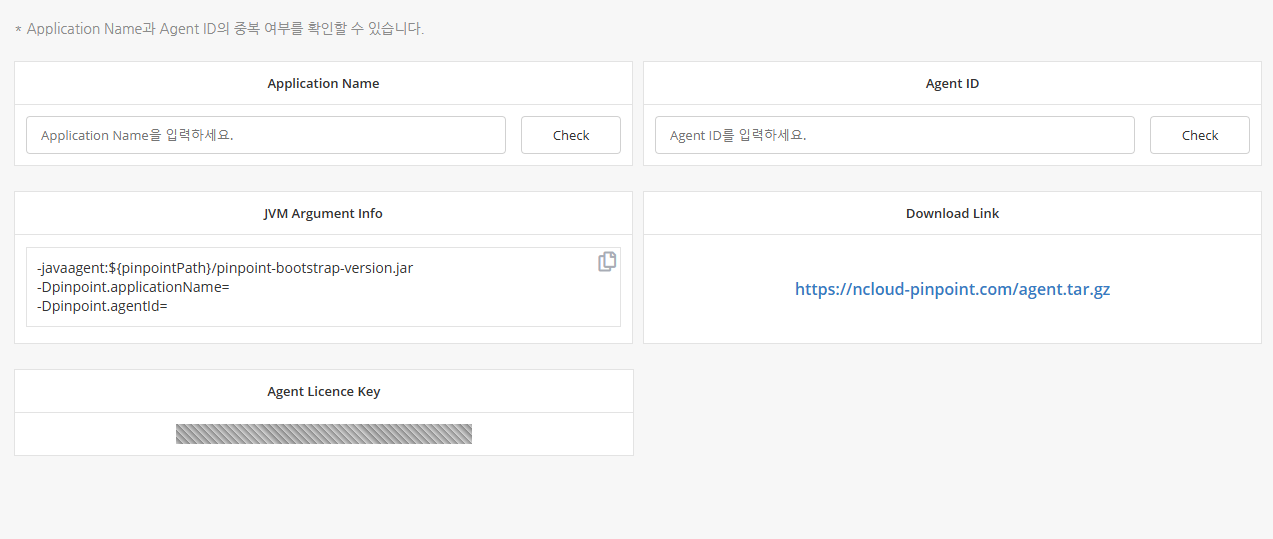
Download Link에 위치한 링크를 클릭해 pinpoint agent 파일을 다운로드 받는다.
이 파일은 모니터링할 서버와 동일한 기기에 설치해야 한다.
다운로드 받은 파일을 모니터링할 서버로 옮긴다.
나는 우선 로컬에 연결해볼 예정이었기 때문에 C드라이브에 압축을 해제했다.
그리고 압축 해제한 파일을 보면 pinpoint.licence 파일이 존재한다. 이 때 위의 화면에 존재하는 Agent Licence Key를 입력하고 저장해주면 된다.
운영환경에 적용
똑같이 EC2 서버에 Agent 파일을 압축해제 해준다.
이후 환경변수 설정을 해주면 되는데,
1
2
3
4
5
6
7
8
9
nano ~/.bashrc
위 명령어에서 아래 내용을 추가.
export pinpointPath={pinpointAgent 경로}
아래 명령어로 환경변수 적용
source ~/.bashrc
1
echo $pinpointPath
위 명령어로 환경 변수가 제대로 설정되었는지 체크하면 된다.
이후 docker-compose 파일에도
1
2
3
4
5
environment:
- JAVA_TOOL_OPTIONS=-javaagent:$pinpointPath/pinpoint-bootstrap-2.3.3-NCP-RC3.jar -DPinpointAgentName= -DpinpointAgentId=
volumes:
- /home/ubuntu/app/pinpoint-agent-2.3.3-NCP-RC3:/home/ubuntu/app/pinpoint-agent-2.3.3-NCP-RC3
과 같이 추가해주면 된다.
오류
버전 호환성, HBase 세팅 문제 등 원인 파악이 힘든 문제들로 위와 같은 방법들에서는 연결이 제대로 되지 않는 문제가 있었다.
우선 정해진 개발 기간 안에 모니터링 도구를 도입하고 싶어 일단 Pinpoint 도입은 미루고, 조금 더 경량화된 APM 도구이지만 대규모 분산 환경에서는 조금 약점을 보이는 Scouter를 적용해보려 한다.
Scouter 도입
Scouter도 Pinpoint와 비슷하게 3가지 구성 요소로 나뉜다.
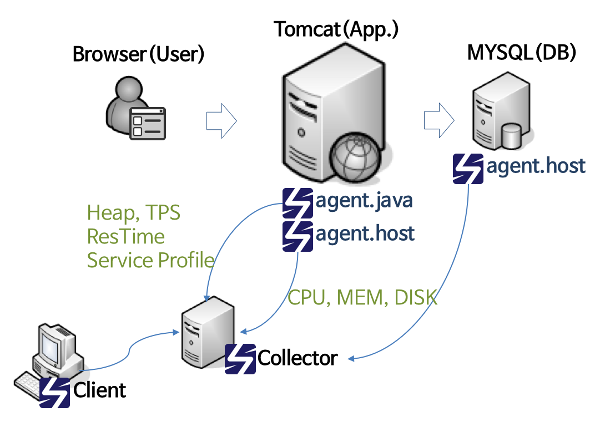
- Scouter Agent: 성능 데이터를 수집한다. 데이터를 Collector로 전송한다.
- Java Agent: Spring Boot, Spring MVC 등 기반의 애플리케이션 성능 모니터링에 사용된다.
- Host Agent: CPU, Memory, 디스크 IO 등 호스트 시스템 메트릭을 수집한다.
- Other Agents: Database, Network와 같은 특정 환경 모니터링 용도이다.
- 애플리케이션 실행 시 Java 에이전트를 -javaagent 옵션으로 추가해 설정한다.
- Scouter Collector: Agent에서 수집한 데이터를 중앙 집중식으로 저장하고 관리한다.
- 데이터를 저장하고 처리해 Scouter Web 또는 CLI 도구에서 볼 수 있도록 제공한다.
- 기본적으로 로컬 파일 시스템에 데이터를 저장하지만, MySQL과 같은 외부 DB와 연동이 가능하다.
- Scouter Web: 수집된 데이터를 웹 기반의 대시보드로 시각화해 보여준다.
- 실시간 트랜잭션 모니터링, SQL 쿼리 추적, 서버 상태 등 다양한 데이터를 제공한다.
Scouter의 장점은 아래와 같다.
- 경량화된 모니터링 도구
- 시스템에 큰 부하를 주지 않고 Agent의 오버헤드가 매우 낮다.
- Collector와 Agent가 단순히 네트워크를 통해 데이터를 주고 받는 구조로 설치와 설정이 간편하다.
- MySQL, Redis, MongoDB등 다양한 데이터베이스 모니터링을 지원한다.
운영환경 도입
위 링크에 가서 우선 Collector, Web UI, Agent를 다운받아야 한다.
물론 Web UI는 선택 옵션이다.
1
wget https://github.com/scouter-project/scouter/releases/download/v2.20.0/scouter-all-2.20.0.tar.gz
위 명령어로 스프링 애플리케이션이 띄워진 EC2 서버에 압축파일을 설치해준다.
1
tar -xvf scouter-all-2.20.0.tar.gz
압축을 풀어준다. scouter라는 새로운 폴더가 생긴다.
Scouter Collector 실행
/scouter/server 경로로 이동해 startup.sh 파일을 실행해준다.
1
$ ./startup.sh
이 때 실행이 안될 수 있는데, EC2 서버에 Java가 설치되어 있어야 한다.
1
netstart -an | grep 6100
명령어로 실행을 확인할 수 있다.
Host Agent 실행
scouter/agent.host/conf 폴더로 이동해 scouter.conf 파일을 변경해준다.
실행하면 모두 주석처리 되어 있을텐데 아래 3줄을 주석처리 해제해준다.
1
2
3
net_collector_ip=127.0.0.1
net_collector_udp_port=6100
net_collector_tcp_port=6100
다시 뒤로 가서 ./host.sh 명령어로 실행해주자.
클라이언트로 Scouter 서버 접속해 확인
스카우터 Github에 접속해 scouter.client.product-win32.win32.x86_64.zip 파일을 로컬 PC 환경에 다운로드 해준다.
압축 해제 후 Scouter.exe를 실행해주면 된다.
이 때 로컬에서도 Java가 설치되어 있어야 한다.
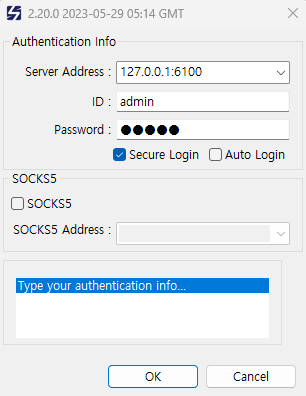
이런 화면이 나타나면 ID, Password 둘 다 모두 admin으로 입력 후 접속해주면 된다.
Server Address는 EC2 서버에 맞게 해줘야 한다.
접속이 안됨
Collector를 실행하면 nohub.out 파일에 로그가 남는다.
알고보니 Java 버전 호환성 문제로 서버가 실행이 안되고 있었다.
Java 17을 설치해놨는데 11버전으로 교체해야 할 것 같다.
교체했더니 정상적으로 실행이 되는 모습을 볼 수 있다.
Java Agent 실행
똑같이 agent.java -> conf -> scouter.conf 파일을 수정해준다.
1
2
3
4
obj_name=WAS-01
net_collector_ip=EC2 private IP
net_collector_udp_port=6100
net_collector_tcp_port=6100
IP를 바꿔주고 위 4줄을 주석 해제 해준다.
그리고 Docker-compose 파일에서 VM 옵션을 추가시켜준다.
1
-JAVA_TOOL_OPTIONS=-javaagent:${경로}/scouter.agent.jar -Dscouter.config=${경로}/conf/scouter.conf
1
2
volumes:
- /home/ubuntu/apm/scouter/agent.java:/home/ubuntu/apm/scouter/agent.java
위와 같은 내용을 도커 컴포즈 파일에 추가해주고 실행해주면 된다.
주의 사항
나는 Docker-Compose를 통해 같은 EC2 서버 내에서 스프링부트 애플리케이션, agent.java가 실행되었다.
그리고 EC2 서버 내에서 Collector를 도커 없이 실행시켰다.
그래서 Agent의 Collector IP는 private IP를 사용해야 하고, 만약 EC2 서버 외부에 있다면 public IP를 사용해야 한다.
단, public IP를 사용하기 위해서는 UDP 6100 포트를 보안그룹에서 열어주어야 한다.
지표 보는법
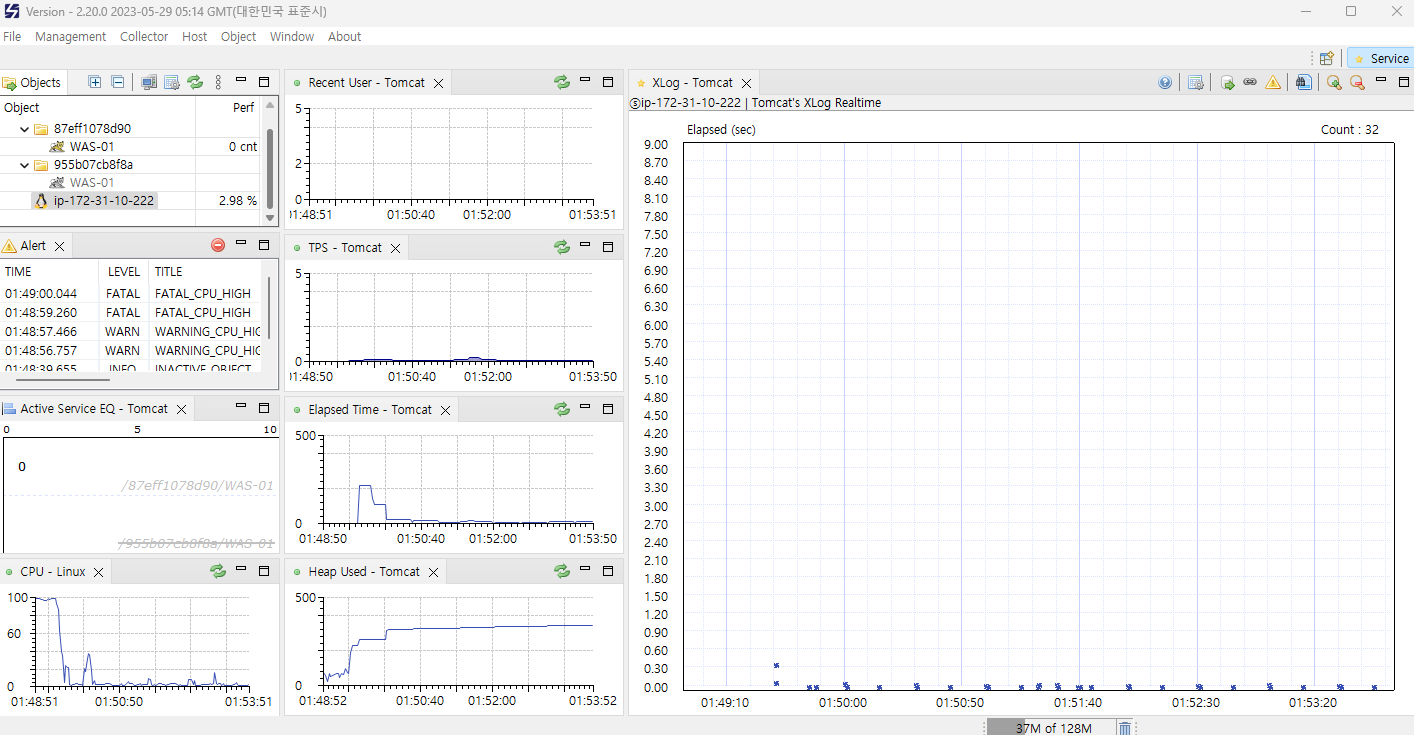
최종적으로 실행되면 위와 같은 화면이 나타나고, 빨간불이 들어왔던 부분들이 초록불로 변하게 된다.
마지막으로 지표를 보는 방법을 소개하고자 한다.
- Object (좌측 상단)
- Scouter에 등록된 대상 애플리케이션 (Agent) 목록을 표시한다.
- WAS, Spring 애플리케이션, Database 등 Agent가 설치된 서비스가 표시된다.
- Alerts (경고)
- 시스템에서 발생한 경고 및 이상 상황을 실시간으로 표시한다.
- CPU 사용량, 메모리 부족, TPS 임계 초과 등 경고 발생 원인을 분석할 수 있다.
- TPS (초당 트랜잭션 수)
- 초당 처리된 트랜잭션 수를 표시한다.
- 특정 시간동안 애플리케이션이 처리한 요청 수를 나타낸다.
- 값이 급격히 증가하거나 감소하면 트래픽 과부하 또는 서비스 중단을 의심해야 한다.
- Active Service EQ (활성 서비스 EQ)
- 현재 실행 중인 요청의 처리 대기 상태를 표시한다.
- 값이 높다면 서비스가 지연되고 있거나 병목 현상이 발생할 가능성이 있다.
- Recent User (최근 사용자)
- 애플리케이션에 최근 접근한 사용자 수를 그래프로 표시해준다.
- Elapsed Time (응답 시간)
- 서비스 요청 처리에 걸린 시간을 표시한다.
- 요청 당 응답 시간이 초 단위로 표시된다.
- 평균 응답 시간이 지속적으로 길다면 쿼리 최적화, 캐싱 적용 등을 검토해야 한다.
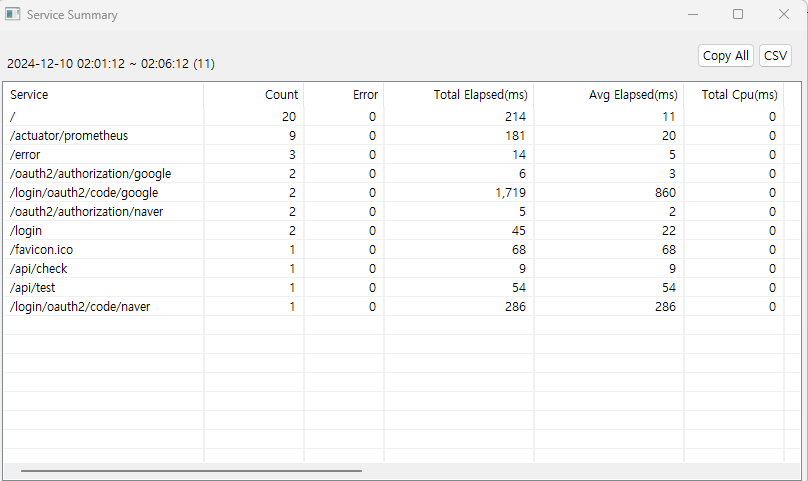
이런식으로 어떤 API가 몇 번 호출됐고, 응답 시간은 얼마나 걸리는 지 등등을 한 눈에 볼 수 있다.