
자녀가 책에 좋아요/싫어요 정보를 남길 수 있는데 그 정보에 따라 선호하는 장르나 선호하는 주제어, 혹은 성향이라고 할 수 있는 MBTI가 바뀌게 되는 시스템을 구현해야 한다.
좋아요/싫어요 누른 모든 책을 조회해서 그 부분을 실시간으로 적용하는 것은 말이 안되고 이미 반영한 책을 제거하는 작업도 필요하기 때문에 좋아요/싫어요를 누르는 행위를 이벤트로 관리해 그 이벤트를 바탕으로 작업을 처리하고자 했다.
해당 이벤트가 발행될 때마다 점수를 update하는 것도 성능에 문제가 있을 수 있기 때문에 이벤트를 발행해놓고 해당 이벤트를 저장한 후 저장한 이벤트에 담긴 정보들을 바탕으로 새 성향을 반영하는 작업은 배치/스케줄러로 처리하기로 결정했다.
이번에 이벤트를 사용하면서 Kafka를 사용해보기로 했고 카프카로 발행한 이벤트 정보는 Redis에 저장해두었다가 사용하기로 했다.
따라서 이번 시스템을 구현하면서 사용한 카프카에 대해 기본적인 정리를 하고 어떻게 구현했는지 정리해보고자 한다.
그리고 왜 스프링 이벤트가 아닌 카프카를 채택했는지도 설명해보고자 한다.
카프카
Kafka는 오픈 소스 분산 메시징 시스템이자 데이터 스트리밍 플랫폼이다. 대량의 데이터를 빠르고 효율적으로 처리하는 데 최적화되어 있다.
주로 실시간 데이터 스트리밍, 비동기 이벤트 처리, 데이터 파이프라인 구성에 많이 사용된다. 이벤트나 메시지를 실시간으로 전송하고 데이터를 다양한 시스템에 전달하는 흐름을 자동화할 수 있다.
기존 데이터 시스템의 문제와 Kafka의 등장
각 애플리케이션과 DB가 end-to-end로 연결되어 있고 요구사항이 늘어남에 따라 데이터 시스템의 복잡도가 높아져왔다. 그러면서 문제가 생기기 시작한다.
- 시스템 복잡도 증가
- 통합된 전송 영역이 없어 데이터의 흐름을 파악하기 어렵다.
- 특정 부분에서 장애가 발생할 시 조치 시간이 증가한다. (연결되어 있는 애플리케이션을 모두 확인해야 한다.)
- HW 교체 / SW 업그레이드 시 관리 포인트가 늘어나고 작업 시간이 늘어난다.
- 데이터 파이프라인 관리의 어려움
- 각 애플리케이션과 데이터 시스템 간의 별도의 파이프라인이 존재하고 파이프라인마다 데이터 포맷과 처리 방식이 다르다.
- 따라서 새로운 파이프라인 확장이 어려워져 확장성 및 유연성이 떨어진다.
이러한 문제들로 인해 모든 시스템으로 데이터를 전송할 수 있으며 실시간 처리도 가능하고 확장이 용이한 시스템이 필요했다.
모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있는 Kafka가 등장한다.
Kafka의 등장 이후
Kafka의 등장 이후 위 문제들이 어떻게 해결됐는지 보자.
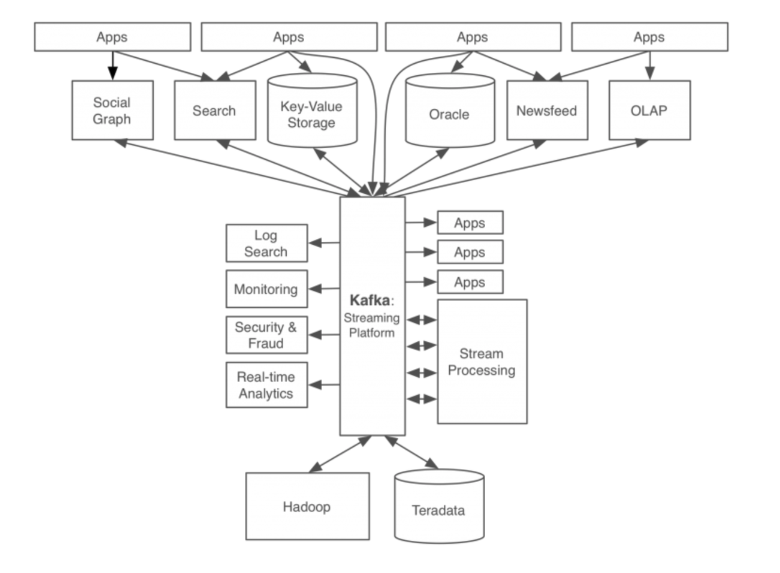
- Kafka라는 플랫폼을 통해 모든 이벤트/데이터의 흐름을 중앙에서 관리한다.
- 새로운 서비스나 시스템이 추가되어도 카프카가 제공하는 표준 포맷으로 연결하면 되기 때문에 확장성과 신뢰성이 증가한다.
- 개발자는 각 서비스간 연결에 신경쓸 필요 없이, 서비스들의 비즈니스 로직에 집중할 수 있다.
Kafka 동작 방식 (Redis, RabbitMQ와 비교)
카프카는 Pub-Sub 모델의 메시지 큐 형태로 동작한다.
카프카에 대해서 더 잘 이해하기 위해 우선 메시지 큐와 이벤트 브로커에 대해 알아보자.
메시지 큐
메시지 큐는 메시지 지향 미들웨어(MOM: Message Oriented Middleware)를 구현한 시스템이다. 프로그램간 데이터를 교환할 때 사용하는 기술이다.
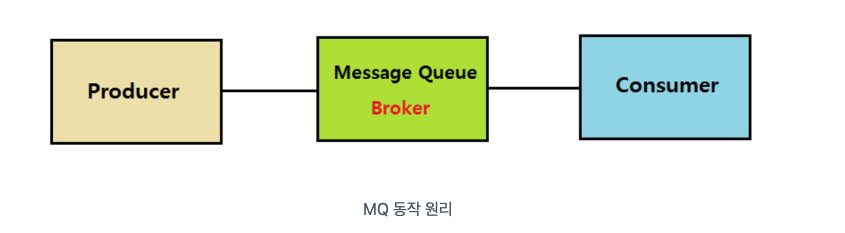
- Producer: 정보를 제공하는 자
- Consumer: 정보를 제공받아 사용하는 자
- Queue: Producer의 데이터를 임시 저장하고 Consumer에 제공하는 역할
MQ에서 메시지는 EndPoint (Producer - Consumer) 간 직접 통신하지 않고 중간 Queue를 통해 중개된다.
- MQ의 장점
- 비동기: Queue라는 임시 저장소가 존재하기 때문에 나중에 처리 가능하다.
- 낮은 결합도: 애플리케이션과 분리되어 있다.
- 확장성: Producer / Consumer 서비스를 원하는대로 확장할 수 있다.
- 탄력성: Consumer 서비스가 다운되더라도 애플리케이션이 중단되지 않고 메시지는 계속 남아있다.
- 보장성: MQ에 들어가면 궁극적으로 모든 메시지가 Consumer 서비스에게 전달됨이 보장된다.
메시지 브로커 / 이벤트 브로커
- 메시지 브로커
- Publisher가 생산한 메시지를 메시지 큐에 저장하고 저장된 데이터를 Consumer가 가져갈 수 있도록 중간다리 역할을 해주는 브로커라고 볼 수 있다.
- 보통 서로 다른 시스템 사이에서 데이터를 비동기로 처리하기 위해 사용한다.
- 이러한 구조를 보통 pub/sub 구조라고 한다.
- 메시지 브로커들은 Consumer가 큐에서 데이터를 가져가게 되면 즉시 혹은 짧은 시간 내에 큐에서 데이터가 삭제되는 특징이 있다.
- ex) Redis, RabbitMQ
- 이벤트 브로커
- 기본적으로 메시지 브로커의 큐 기능을 가지고 있어 메시지 브로커의 역할도 할 수 있다.
- 다만 메시지 브로커와의 차이는 Publisher가 생산한 이벤트를 이벤트 처리 후 바로 삭제하지 않고 저장한다.
- 즉, 이벤트 시점이 저장되어 있어 Consumer가 특정 시점부터 이벤트를 다시 Consume 할 수 있는 장점이 있다.
- 또한 대용량 처리에 있어 메시지 브로커보다 더 많은 양의 데이터를 처리할 수 있다.
- ex) Kafka, AWS kinesis
Pub/Sub 모델
일반적인 형태의 네트워크 통신은 아래 그림과 같다.
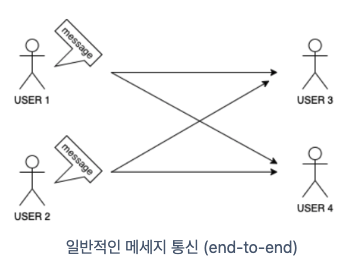
각 개체가 직접 연결하며 통신한다.
당연하게도 전송속도가 빠르고 전송 결과를 신속하게 알 수 있다는 장점이 있다.
단, 특정 개체에 장애가 발생할 경우 메시지를 보내는 쪽에서 대기 처리 등을 개별적으로 해주지 않으면 장애가 전파될 수 있고, 참여하는 개체가 많아질수록 각 개체를 연결해줘야 하기 때문에 시스템이 커질수록 확장성이 좋지 않다는 단점을 가진다.
이런 형태의 단점들을 극복하고자 나온 것이 Pub/Sub 모델이다.
Pub/Sub 모델
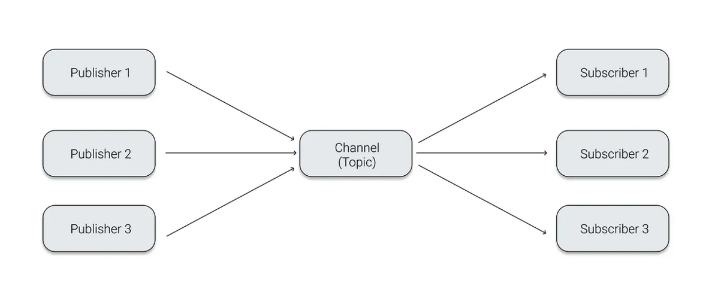
비동기 메시지 전송 방식으로, 발신자의 메시지에는 수신자가 정해져 있지 않은 상태로 publish 된다.
그리고 이를 Subscribe한 수신자만 정해진 메시지(Topic)을 받을 수 있다.
수신자의 입장에서는 발신자 정보가 없어도 원하는 메시지만 수신할 수 있고 이 구조를 통해 높은 확장성을 확보할 수 있다.
Pub/Sub 모델의 구체적인 발행/구독 방식은 각 서비스마다 다르다.
대표적으로 Kafka, Redis, RabbitMQ 등이 존재하는데 이를 비교해보자.
Kafka, Redis, RabbitMQ 비교
Pub/Sub 모델을 사용하는 각 서비스의 장단을 비교해보자.
Redis
Redis는 데이터베이스, 캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 인메모리 기반 저장소이다.
- 구성 요소
- Publisher: 메시지를 게시 (pub)
- Channel: 메시지를 쌓아두는 저장소 (queue)
- Subscriber: 메시지를 구독 (sub)
- 동작
- Publisher가 Channel에 메시지를 게시한다.
- 해당 Channel을 구독하고 있는 Subscriber가 메시지를 받아 처리한다.
- 특징
- Channel은 이벤트를 저장하지 않는다.
- Channel에 이벤트가 도착했을 때 해당 채널의 Subscriber가 존재하지 않는다면 이벤트가 그냥 사라진다.
- Subscriber는 동시에 여러 Channel을 구독할 수 있고, 특정한 Channel을 지정하지 않아도 패턴을 설정하여 해당 패턴에 맞는 채널을 구독하게 할 수도 있다.
- 장점
- 처리 속도가 빠르다.
- 캐시의 역할도 가능하다.
- 명시적으로 데이터의 삭제도 가능하다.
- 단점
- 메모리 기반이기 때문에 서버가 다운되면 Redis 내 모든 데이터가 사라진다.
- 이벤트의 도착을 보장하지 않는다.
RabbitMQ
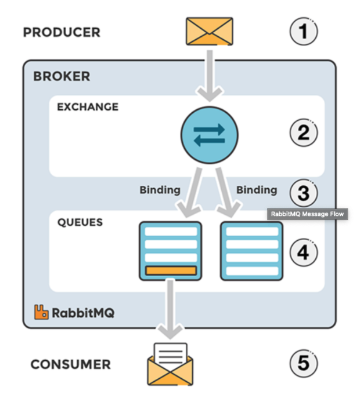
RabbitMQ는 AMQP 프로토콜 (Advanced Message Queuing Protocol)을 구현한 메시지 브로커이다.
AMQP 프로토콜이란 메시지 지향 미들웨어를 위한 개방형 표준 응용 계층 프로토콜이다. Client와 Middleware broker간의 메시지를 주고받기 위한 프로토콜이다.
- 구성 요소
- Producer: 메시지를 보낸다.
- Exchange: 메시지를 목적지(Queue)에 맞게 전달한다.
- Queue: 메시지를 저장한다.
- Consumer: 메시지를 받아 처리한다.
- 메시지 처리 과정
- Producer가 Broker로 메시지를 보낸다.
- Broker 내의 Exchange에서 해당하는 key에 맞게 Queue에 분배한다.
- Topic 모드: Routing Key가 정확히 일치하는 Queue에 메시지 전송 (Unicast)
- Direct 모드: Routing Key 패턴이 일치하는 Queue에 메시지 전송 (Multicast)
- Headers 모드: Key:Value로 이루어진 Header 값을 기준으로 일치하는 Queue에 메시지 전송 (Multicast)
- Fanout 모드: 해당 Exchange에 등록된 모든 Queue에 메시지 전송 (Broadcast)
- Queue에서 Consumer가 메시지를 받는다.
- 장점
- Broker를 중심으로 Publisher와 Consumer 간 메시지 전달 보장에 초점을 맞추고, 복잡한 라우팅을 지원한다.
- 클러스터의 구성이 쉽고 Manage UI가 제공되며 플러그인도 제공되어 확장성이 뛰어나다.
- 20KB/sec 정도의 속도를 가진다.
- 데이터 처리의 측면보다 관리의 측면에서 다양한 기능 구현을 위한 서비스를 구축할 때 사용하기 용이하다.
- 단점
- MQ Server가 종료 후 재기동되면 Queue의 내용은 모두 제거된다.
- 성능 문제가 존재한다.
- Producer와 Consumer 간의 결합도가 높다.
Kafka
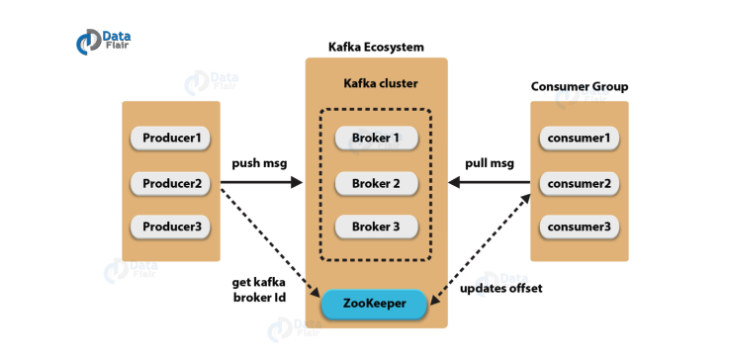
- 구성 요소
- Event: Kafka에서 Producer와 Consumer가 데이터를 주고받는 단위 (message)
- Producer: Kafka에 이벤트를 게시(Post, Pop)하는 클라이언트 애플리케이션
- Consumer: Topic을 구독하고 이로부터 얻어낸 이벤트를 받아 처리하는 클라이언트 애플리케이션
- Topic: 이벤트가 모이는 곳으로 Producer는 Topic에 이벤트를 게시하고 Consumer는 Topic을 구독해 이로부터 이벤트를 가져와서 처리한다.
- Partition: Topic은 여러 Broker에 분산되어 저장되는데, 이렇게 분산된 topic을 Partition이라고 한다.
- ZooKeeper: 분산 메시지의 Queue 정보를 관리한다.
- 동작 방식
- Publisher는 전달하고자 하는 메시지를 Topic을 통해 카테고리화 한다.
- Subscriber는 원하는 Topic을 구독함으로써 메시지를 읽어온다.
- Publisher와 Subscriber는 Topic 정보만 인지하고, 서로에 대한 정보는 알지 못한다.
- Kafka는 Broker들이 하나의 클러스터로 구성되어 동작하도록 설계되어 있다. 클러스터 내 Broker에 대한 분산 처리는 ZooKeeper가 담당한다.
- 장점
- 대규모 트래픽 처리 및 분산 처리에 효과적이다.
- 클러스터 구성, Fail-over, Replication 같은 기능이 있다.
- 100KB/sec 정도의 속도로 다른 MQ보다 빠르다.
- 디스크에 메시지를 특정 보관 주기동안 저장하여 데이터의 영속성이 보장되고 유실 위험이 비교적 적다. 또한 이를 통해 Consumer 장애 시 재처리를 할 수 있다.
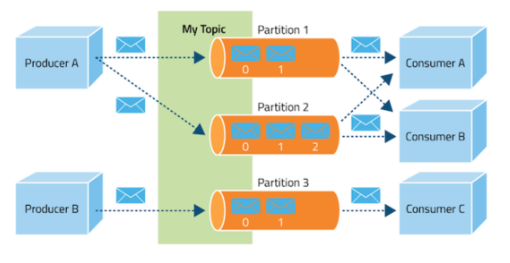
Partition
Topic을 여러 Broker에 나누어 분산 저장하기 위한 단위이다.
Topic의 데이터가 하나의 저장소에 모두 쌓이는 것이 아닌 여러 Partition에 나누어 저장되어 분산 처리와 병렬 처리를 가능하게 한다.
Topic 생성 시 Partition의 개수를 지정할 수 있고 Partition 내부에서는 각 메시지가 Offset으로 구분된다.
- 하나의 Topic이 여러 Partition으로 나뉘면 각 Partition에 대해 별도의 Consumer가 동작할 수 있기 때문에 병렬 처리가 가능하다.
- 예를 들어 10개의 Partition이 존재한다면 최대 10개의 Consumer가 동시에 데이터를 처리할 수 있다.
- Partition을 통해 데이터를 고르게 분배하여 시스템 성능을 균일하게 유지할 수 있다.
- 각 Partition 내에서 데이터의 순서는 보장된다. 하지만 다른 Partition간에는 순서가 보장되지 않아 순서가 중요한 경우 키를 기반으로 특정 Partition에 데이터를 고정시켜야 한다.
Offset
Consumer에서 메시지를 어디까지 읽었는지 알 수 있도록하는 값이다.
- Consumer 그룹의 Consumer들은 각각의 파티션에 자신이 가져간 메시지의 위치 정보를 기록한다.
- Consumer에 장애 발생 후 다시 복구해도 전에 마지막으로 읽었던 위치부터 다시 처리할 수 있도록 해준다.
Consumer Group
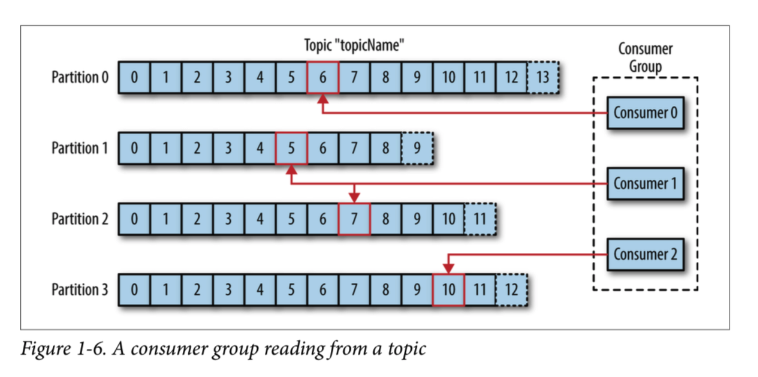
- Consumer Group은 하나의 Topic에 대해 책임을 갖고 있다.
- 어떤 Consumer가 다운되었을 경우 파티션 재조정을 통해 다른 컨슈머가 해당 파티션의 Sub를 맡아서 한다.
- Offset 정보를 그룹 간 공유하고 있어 다운되기 전 마지막으로 읽었던 메시지 위치부터 시작할 수 있다.
비교
| Kafka | RabbitMQ | Redis Pub/Sub | |
|---|---|---|---|
| 라우팅 | 기본 기능으로 라우팅에 대해 지원하지 않음. Kafka Streams를 활용해 동적 라우팅을 구현할 수 있다. | Direct, Fanout, Topic, Headers의 라우팅 옵션을 제공한다. | - |
| 프로토콜 | 단순한 메시지 헤더를 지닌 TCP 기반 Custom 프로토콜을 사용해 대체가 어렵다. | AMQP, MQTT, STOMP 등 여러 메시징 플랫폼을 지원한다. | RESP (Redis Serialization Protocol) - TCP 통신 |
| 우선 순위 | 변경 불가능한 시퀀스 큐로, 한 파티션 내에서는 시간 순서를 보장하지만 여러 파티션이 병렬로 처리할 때는 순서 보장이 불가하다. | Priority Queue를 지원해 우선 순위에 따라 처리가 가능하다. | 우선순위 처리 불가 |
| 이벤트 저장 | 이벤트를 삭제하지 않고 디스크에 저장해 영속성이 보장되고 재처리가 가능하다. | 메시지가 성공적으로 전달되었다고 판단될 경우 메시지가 큐에서 삭제되어 재처리가 어렵다. | 저장하지 않는다. |
- 대용량 데이터 처리, 실시간, 고성능, 고가용성이 필요한 경우 혹은 저장된 이벤트를 기반으로 로그를 추적하고 재처리가 필요한 경우 Kafka를 사용
- 복잡한 라우팅을 유연하게 처리해야 하고 정확한 요청-응답이 필요한 Application을 사용할 때 혹은 트래픽은 작지만 장시간 실행되고 안정적은 백그라운드 작업이 필요한 경우 RabbitMQ 사용
- 이벤트 데이터를 DB에 저장하기 때문에 굳이 미들웨어에 이벤트를 저장할 필요가 없는 경우, Consumer에게 반드시 알람이 도착해야 한다는 보장이 필요없다면 유지보수가 편한 Redis를 사용
Kafka 설치 및 테스트
카프카를 사용하기 위해 설치하고 SpringBoot 환경에서 어떻게 사용하는 지 보자.
- 윈도우 기준 Kafka와 Zookeeper를 설치해준다.
- 압축 파일을 설치하게 되고, 각 파일을 압축 해제해준다.
- 이 때 해당 파일들의 경로 이름이 길면 추후 실행할 때 입력 줄이 너무 깁니다. 명령 구문이 올바르지 않습니다. 라는 문구의 문제가 발생한다.
- 따라서 단순하게 C드라이브 아래나, 간단한 경로의 위치에 위치시켜준다.
설치가 완료되면 아래와 같은 설정을 할 수 있다.
압축 해제한 kafka 폴더에 logs라는 폴더를 만들고, config 폴더의 server.properties를 열어 아래 log.dirs를 해당 경로로 수정해주면 발생하는 로그가 해당 폴더로 저장되게 된다.
1
log.dirs=C:\kafka\logs
그리고 Zookeeper는 conf 폴더에 zoo_sample 파일이 있는데 해당 파일을 복사해 zoo라는 파일을 만들어주고,
1
dataDir=C:\zookeeper\data
data 폴더를 만들어 준 후 위와 같이 경로를 설정해주면 data를 해당 경로에 저장할 수 있다.
실행
우선 Zookeeper를 실행한다.
Zookeeper를 압축해제한 폴더가 아닌 Kafka를 압축해제한 폴더 경로로 이동한 후 아래 명령어를 입력하면 된다.
1
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
실행을 확인하고 Kafka를 실행하면 된다.
Kafka의 실행은 마찬가지로 Kafka를 압축해제한 경로로 가서
1
bin\windows\kafka-server-start.bat config\server.properties
명령어를 입력해 실행해주면 된다.
SpringBoot 설정
1
2
implementation 'org.springframework.kafka:spring-kafka'
implementation 'org.apache.kafka:kafka-clients'
위 의존성들을 추가해준다.
- org.springframework.kafka:spring-kafka
- Spring 프레임워크 위에서 Kafka를 편리하게 사용할 수 있도록 지원한다.
- DI, AOP 등을 활용해 Kafka를 쉽게 구성하고 관리할 수 있도록 도와준다.
- 예를 들면 Kafka 메시지 리스너를 쉽게 구현하고 관리할 수 있고, Kafka 트랜잭션 관리 및 에러 처리 등을 Spring과 일관된 방식으로 처리할 수 있다.
- org.apache.kafka:kafka-clients
- Apache Kafka와 직접적으로 통신하기 위한 클라이언트 API를 제공한다.
- Producer와 Consumer 등 Kafka와 직접적으로 데이터를 주고받기 위한 기본적인 클라이언트 기능들을 포함한다.
- Java 언어로 Kafka를 사용할 때 기본적으로 필요한 라이브러리이다.
그리고 properties 설정을 해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# Consumer 설정
# Kafka 컨슈머가 연결할 브로커의 주소입니다. 여기서는 로컬에서 실행 중인 Kafka 브로커의 주소와 포트를 지정하고 있습니다.
spring.kafka.consumer.bootstrap-servers=localhost:9092
# 컨슈머 그룹의 ID를 설정합니다. 이 ID는 Kafka 클러스터 내에서 이 컨슈머 그룹을 식별하는 데 사용됩니다.
spring.kafka.consumer.group-id=test-consumer-group
# 오프셋이 초기화되어야 하는 상황(예: 처음 시작하는 컨슈머, 또는 오프셋이 더 이상 유효하지 않은 경우)에 사용할 오프셋 초기화 정책을 설정합니다.
# 'earliest'는 토픽의 처음부터 메시지를 읽기 시작하겠다는 것을 의미합니다.
spring.kafka.consumer.auto-offset-reset=earliest
# Kafka로부터 메시지의 키를 역직렬화하는 데 사용할 클래스를 지정합니다. 여기서는 문자열 역직렬화 클래스를 사용하고 있습니다.
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# Kafka로부터 메시지의 값을 역직렬화하는 데 사용할 클래스를 지정합니다. 여기서도 문자열 역직렬화 클래스를 사용하고 있습니다.
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# Producer 설정
# Kafka 프로듀서가 연결할 브로커의 주소입니다. 컨슈머 설정과 마찬가지로 로컬에서 실행 중인 Kafka 브로커의 주소와 포트를 지정하고 있습니다.
spring.kafka.producer.bootstrap-servers=localhost:9092
# Kafka로 메시지를 보낼 때 메시지의 키를 직렬화하는 데 사용할 클래스를 지정합니다. 여기서는 문자열 직렬화 클래스를 사용하고 있습니다.
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
# Kafka로 메시지를 보낼 때 메시지의 값을 직렬화하는 데 사용할 클래스를 지정합니다. 여기서도 문자열 직렬화 클래스를 사용하고 있습니다.
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
코드 테스트
1
2
3
4
5
6
7
8
9
10
@RestController
@RequiredArgsConstructor
public class KafkaController {
private final KafkaProducerService producer;
@PostMapping("/send")
public void send(@RequestParam("message") String message){
producer.sendMessage("test",message);
}
}
1
2
3
4
5
6
7
8
9
10
@Service
@RequiredArgsConstructor
public class KafkaProducerService {
private final KafkaTemplate<String,String> kafkaTemplate;
public void sendMessage(String topic, String message){
kafkaTemplate.send(topic,message);
}
}
여기서 보낸 메시지를 KafkaListener를 통해 처리할 수 있다.
1
2
3
4
5
6
7
@Service
public class KafkaConsumerService {
@KafkaListener(topics = "test", groupId = "test-consumer-group")
public void consume(String message){
System.out.println("Received Message in group 'test-consumer-group': " + message);
}
}
수행해보면 메시지가 보내졌을 때 Listener를 통해 처리하여 결과 문구가 출력되는 것을 확인할 수 있다.
카프카 vs 스프링 이벤트
우선 내 구현을 살펴보기 전, 이전 미니프로젝트에서는 스프링 이벤트를 선택했고, 이번 프로젝트에서는 카프카를 선택했기 때문에 둘을 비교해보도록 하자.
스프링 이벤트
- 장점
- 간단한 설정: 스프링 프레임워크 내부에서 설정하고 사용하여 추가적으로 외부 인프라가 필요하지 않다.
- 빠른 반응 스프링 내에서 발생하는 이벤트에 대해 거의 즉각적으로 반응이 가능하다.
- 트랜잭션 통합 가능: 스프링 내 트랜잭션과 쉽게 통합할 수 있어 데이터의 일관성을 유지하기 쉽고 로컬 이벤트 처리에 유리하다.
- 단점
- 분산 시스템에 부적합: 스프링 이벤트는 기본적으로 단일 애플리케이션 내에서 동작하기 때문에 마이크로서비스 간 이벤트 전달에 적합하지 않다.
- 확장성 제한: 대규모 트래픽을 처리하는 데 한계가 있다. 다수의 이벤트를 동시에 처리하는 경우 성능이 저하될 수 있다.
- 내부 이벤트 사용 권장: 스프링 이벤트는 같은 애플리케이션 내의 로컬 이벤트로 사용하는 것을 권장한다.
카프카 + Redis 선택 이유
똑같이 이벤트를 발행하고, 그 이벤트를 Redis에 저장하는 방식은 동일한데 왜 카프카를 선택했을까.
가장 큰 차이는 일단 카프카는 대용량 이벤트 처리 및 확장성에서 장점이 있다.
그런데 이번 프로젝트 요구사항에 내가 구현하려는 기능과는 크게 관련이 없지만, 이벤트 응모 시스템이 있는데 그 이벤트 응모 시스템의 요구 사항 중 1분간 10만 요청을 10분간 받아내야하는 요구사항이 있었다.
따라서 그 부분을 구현하려면 카프카와 레디스를 활용할 수 있다는 힌트를 얻었고, 그 부분을 구현하는 김에 현재 기능도 많은 요청과 확장성을 고려해야 한다고 가정하여 카프카를 채택해 구현하게 되었다.
구현
우선 도서에 좋아요/싫어요를 눌렀을 때 이벤트를 발행해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Slf4j
@Service
@RequiredArgsConstructor
public class BookLikeService {
private final KafkaUtil kafkaUtil;
public void likeBook(Long childProfileId, Long bookId) {
String message = childProfileId + ":" + bookId + ":LIKE";
kafkaUtil.sendMessage(BOOK_LIKE.getTopicName(), message);
log.info("send msg Kafka - childProfileId: {}, bookId: {}", childProfileId, bookId);
}
public void dislikeBook(Long childProfileId, Long bookId) {
String message = childProfileId + ":" + bookId + ":LIKE";
kafkaUtil.sendMessage(BOOK_DISLIKE.getTopicName(), message);
log.info("send msg Kafka - childProfileId: {}, bookId: {}", childProfileId, bookId);
}
}
물론 이 좋아요/싫어요에는 다른 로직이 더 필요하지만, 우선 메시지를 보내는 부분만 구현을 해놓았다.
이렇게 보낸 메시지를 KafkaListener를 통해 처리한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Slf4j
@Service
@RequiredArgsConstructor
public class KafkaEventHandlingService {
private final RedisUtil redisUtil;
@KafkaListener(topics = {BOOK_LIKE_TOPIC, BOOK_DISLIKE_TOPIC}, groupId = "child-profile-group")
@Transactional
public void processEvent(String message) {
String[] data = message.split(":");
String childProfileId = data[0];
String bookId = data[1];
List<Object> events = redisUtil.getAllFromList(BOOK_LIKE_EVENT_LIST.getKey());
events.removeIf(event -> ((String) event).startsWith(childProfileId + ":" + bookId + ":"));
events.add(message);
redisUtil.deleteList(BOOK_LIKE_EVENT_LIST.getKey());
events.forEach(event -> redisUtil.pushToList(BOOK_LIKE_EVENT_LIST.getKey(), event));
log.info("save event to redis: {}", message);
}
}
해당하는 Topic의 이벤트가 발행되면 처리한다.
Redis에 해당 이벤트 정보를 포함한 메시지를 리스트에 저장하는 방식이다. 만약 좋아요/싫어요를 이미 누른 책에서 좋아요/싫어요를 변경한 경우도 있을 수 있으므로 중복된 BookId가 있을 경우 제거하고 다시 이벤트를 삽입하는 과정을 거친다.
그리고 이렇게 Redis에 저장된 이벤트들을 바탕으로 점수를 업데이트하고, 해당 점수를 바탕으로 자녀 성향을 구한 뒤 그 성향을 히스토리로 생성해 저장하는 로직을 갖게 된다.
이 작업은 배치/스케줄러로 동작하게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
@Slf4j
@Configuration
@RequiredArgsConstructor
public class ChangePersonalityBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final RedisUtil redisUtil;
private final ChildProfileService childProfileService;
private final PersonalityScoreService personalityScoreService;
private final ChildPersonalityHistoryService historyService;
private final BookService bookService;
@Bean
public Job processLikeDislikeEventsJob() {
return new JobBuilder("processLikeDislikeEventsJob", jobRepository)
.start(processLikeDislikeEventsStep())
.build();
}
@Bean
public Step processLikeDislikeEventsStep() {
return new StepBuilder("processLikeDislikeEventsStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(redisEventReader())
.processor(eventProcessor())
.writer(eventWriter())
.build();
}
@Bean
@StepScope
public ItemReader<String> redisEventReader() {
List<Object> eventObjects = redisUtil.getAllFromList(BOOK_LIKE_EVENT_LIST.getKey());
List<String> events = eventObjects.stream()
.map(Object::toString)
.toList();
return new ListItemReader<>(events);
}
@Bean
public ItemProcessor<String, String> eventProcessor() {
return message -> {
String[] data = message.split(":");
Long childProfileId = Long.parseLong(data[0]);
Long bookId = Long.parseLong(data[1]);
String action = data[2];
ChildProfile childProfile = childProfileService.getChildProfileWithMBTIScore(childProfileId);
Book book = bookService.getBookWithCache(bookId);
double changedScore = action.equals("LIKE") ? 2.0 : -2.0;
personalityScoreService.updateGenreAndTopicScores(childProfile, book, changedScore);
createAndUpdateHistory(childProfile);
return message;
};
}
@Bean
public ItemWriter<String> eventWriter() {
return messages -> {
redisUtil.deleteList(BOOK_LIKE_EVENT_LIST.getKey());
log.info("Processed and removed events from Redis: {}", messages.size());
};
}
private void createAndUpdateHistory(ChildProfile childProfile) {
MBTIScore currentMBTIScore = MBTIScore.fromCumulativeScore(childProfile.getCumulativeMBTIScore());
ChildPersonalityHistory history = historyService.createHistory(
childProfile.getId(),
currentMBTIScore,
HistoryCreatedType.FEEDBACK
);
List<GenreScore> genreScores = childProfile.getGenreScores();
List<TopicScore> topicScores = childProfile.getTopicScores();
historyService.updatePreferredGenresByScore(history, genreScores);
historyService.updatePreferredTopicsByScore(history, topicScores);
log.info("Create History - ChildProfile ID: {}", childProfile.getId());
}
}
스케줄러 코드는 생략하고, Job을 구현한 부분이다.
이 때 고려한 부분은 이벤트 처리 시 해당 이벤트가 Profile이나 BookId 순서대로 되어있지 않기 때문에 각 작업을 할 때 이미 조회했던 Profile이나 Book을 사용하게 되는데, 중복된 부분도 계속 반복 조회하는 것에서 성능 개선점이 있을 것이라고 판단했다.
그래서 처음에는 Profile과 Book 모두를 캐싱하는 방식을 썼다.
그런데 고민해보니 History를 저장할 때 Profile에 연결되어 변경감지를 사용한 저장이 이루어지는데, Profile을 캐싱해 사용하면 영속성 컨텍스트에 영속되지 않아 변경 감지가 동작하지 않는 문제가 있었다.
따라서 Profile은 캐싱 후 다시 영속시키는 것 보다는 캐싱없이 계속 영속성 컨텍스트에 관리되도록 하는 것이 나을 것 같아 수정하고, Book 정보는 이미 조회한 정보라면 캐시된 데이터를 사용하도록 수정하였다.
그리고 Step을 생성할 때 Tasklet을 사용하지 않고 Chunk 방식을 사용해 성능 개선을 목표했다.
결과
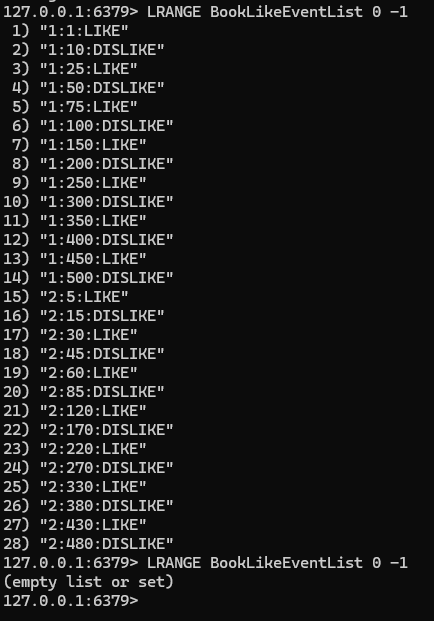
배치 처리 후 Redis 이벤트는 사라졌다.

그리고 History가 정상적으로 생기는 것을 볼 수 있음. false 옆 1이 FEEDBACK 타입으로 생겼다는 의미이다.

Chunk 방식

Tasklet 방식
정상적으로 History가 생성됨을 볼 수 있었다.
그러나 Tasklet 방식이 현재 성능이 더 좋다.
- 데이터셋이 현재 작기 때문에 한 번의 트랜잭션 내에서 모든 작업을 처리하는 Tasklet 방식이 오버헤드가 더 작은 것이 이유이다.
- 반면 Chunk 방식은 일정 크기마다 트랜잭션을 커밋한다.
- 따라서 데이터셋이 클 때 각 청크마다 트랜잭션을 커밋하게 되므로 메모리 사용량을 줄이고 안정성을 높일 수 있다.
- 대용량 작업 시 실패 시 전체 작업을 롤백하지 않고 이미 커밋된 부분을 유지한 후 남은 부분을 재시도 할 수 있다.
- 그리고 대용량 데이터를 한 번에 처리하려면 모든 데이터를 메모리에 올려야 하는데 Tasklet 방식은 이 부분에서 문제가 발생할 수 있다.
결론적으로 현재 테스트로 한 데이터의 크기 정도는 Tasklet 방식이 유리한 것을 확인할 수 있었지만 이번 프로젝트는 대용량 트래픽, 대규모 데이터를 가정하고 하고 있기 때문에 Chunk 방식으로 구현을 유지하기로 했다.