
기존에 파이썬으로 구현했던 웹툰 추천 알고리즘을 다듬어서 Java로 작성해보았다.
작성한 개인화 웹툰 추천 로직에 대해 설명해보려 한다.
추천 시나리오
- 사용자는 최소 10개 이상의 자기가 본 웹툰에 대한 평가를 한다.
- 평가는 1~5점으로 부여한다. (1, 2, 3, 4, 5)
- 평가가 이루어지면, 사용자의 평가데이터, 사용자의 정보를 바탕으로 추천 웹툰을 계산한다.
즉 사용자는 회원가입을 통한 정보, 자기가 본 웹툰에 대한 평가데이터를 제공하면 그 내용을 바탕으로 추천 알고리즘이 동작한다.
- 추천 알고리즘
- 사용자 성별, 나이, MBTI를 바탕으로 코사인 유사도를 구해 유사한 유저를 찾는다.
- 사용자의 평가 데이터를 바탕으로 평가가 유사한 유저를 찾는다.
- 평가 데이터에 대한 유사도는 평가한 웹툰 그 자체와 부여한 평점에 따라 결정된다.
- 두 유사도를 가중치를 부여해 합쳐 하나의 코사인 유사도를 구한다.
- 유사도가 비슷한 K만큼의 이웃을 찾고, 해당 이웃들이 자주, 높게 평가한 웹툰을 추천하게 된다.
MBTI 기준
- MBTI는 16가지 분류를 사용하는 것이 아닌, TJ, TP, FJ, FP 4가지의 분류를 이용한다.
이렇게 뒷 두자리의 MBTI 조합을 고려하는 이유는 해당 조합에서 두드러지는 선호 웹툰 장르의 차이가 있었기 때문이다.
선호 웹툰 장르에 대한 설문조사를 실시했을 때, 단순 I vs E, ISTJ vs ENFP 등의 차이 등등 선호 장르의 차이를 확인해보았을 때 아래와 같이 다른 조합의 차이에 비해 비교적 큰 차이가 있었다.
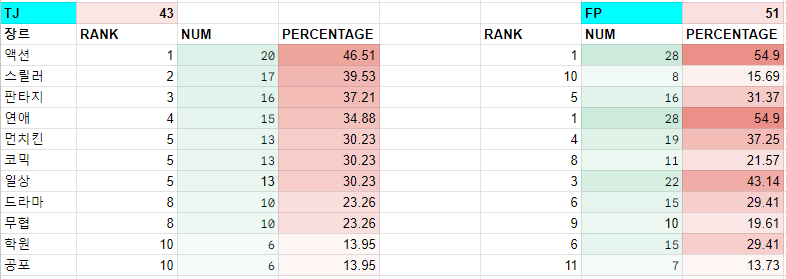
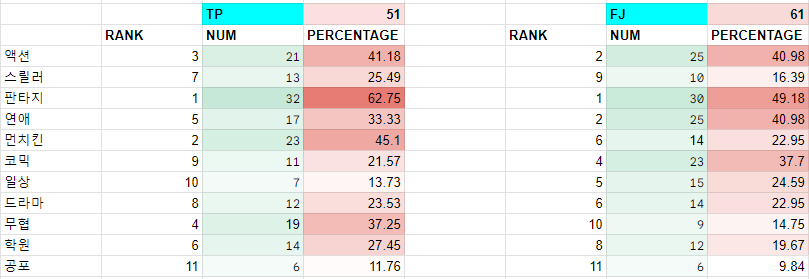
대체적으로 인기있는 판타지, 액션 장르는 비슷하지만 스릴러, 일상, 연애 등의 장르에서 다른 MBTI 조합에 비해 큰 차이를 보인다.
일례로 일상 장르의 경우 T와 P에서 각각 9위, 3위를 차지하고 있는데, TP를 조합했을 때 일상 장르는 선호장르 10위인 최하위권을 차지하고 있다.
설문 조사의 절대적인 크기가 적기 때문에 정확성이 떨어질 수 있지만 우선 결과를 바탕으로 구현을 진행했다.
협업 필터링
위의 시나리오는 협업 필터링 (Collaborative Filtering)을 이용한 것이다.
협업 필터링이란 사용자의 구매 패턴이나 평점을 가지고 다른 사람들의 구매 패턴, 평점을 통해 추천을 하는 방법이다.
해당 방식을 구현하기 위해 KNN - K Nearest Neighbors 알고리즘을 사용했다.
가장 유사한 K명의 이웃을 통해 사용자가 평가하지 않은 웹툰에 대한 예측치를 제공하는 것이다.
- 장점
- 간단하고 직관적인 접근 방식을 통해 구현 및 디버그가 쉽다.
- 추천의 기준이 명확하다.
- 추천 리스트에 새로운 Webtoon이나 User가 추가되어도 상대적으로 안정적이다.
- 단점
- 시간, 속도, 메모리가 많이 필요하다.
- 범위가 제한적이다. 만약 유사도는 비슷한 이웃이 어떤 Webtoon을 아무도 평가하지 않았다면 그 Webtoon에 대한 추천은 이루어지지 않는다.
이 방식은 유사도가 비슷한 이웃의 평가 점수의 평균이 낮거나 높으면 정확한 추천이 될 수 없기 때문에 각 이웃의 평가 점수의 평균을 이용해 보완한다.
그리고 보통 어떤 Webtoon에 대한 예측치를 적용해 유사성 점수가 높은 Webtoon을 추천하는 방식으로 구현하지만 내 알고리즘에서는 유사성이 높은 유저들이 자주, 높게 평가한 웹툰을 추천하는 방식으로 구현했다.
MBTI별 선호 웹툰
- 초기에 데이터가 쌓이지 않았을 때 각 MBTI별 선호 장르 상위 4가지 장르를 통해 장르에 해당하는 랜덤한 웹툰을 추출하여 보여준다.
- 한 논문에 따르면 전체 영화나 음악의 10% 해당하는 초기 상호 작용 데이터가 있을 경우 추천 시스템의 정확도가 크게 향상된다는 결과가 있다.
- 따라서 전체 웹툰 약 550개의 10%인 55개의 평가가 각 MBTI별로 쌓였을 경우, 해당 MBTI 유저들이 평가한 웹툰을 평가 수, 평점에 따른 내림차순으로 나열해 MBTI별 선호 웹툰을 보여준다.
구현(개인화 추천 로직)
MBTI별 선호 웹툰 로직은 단순 정렬 및 필터링이므로 생략하고, Collaborative Filtering을 구현한 구현부를 설명한다.
1
2
3
4
5
6
int[] neighbors = KnnGetNeighbors(loginUser, userEvaluations, K);
Set<Webtoon> recommendationResult = getRecommendationResults(neighbors, userEvaluations, loginUser);
saveRecommendationResults(userRecommendation, evaluationCount, recommendationResult);
return recommendationResult;
- Service 계층에서 정리된 코드이다.
- 유사한 이웃을 구하는 KnnGetNeighbors() 메서드로 이웃을 구한 후 해당 이웃 데이터를 통해 추천 웹툰 결과를 구하고, 저장한다.
1
2
3
4
5
6
7
8
9
10
11
private int[] KnnGetNeighbors(Account loginUser, List<Evaluation> userEvaluations, int K) {
List<Account> allUsers = accountRepository.findAll();
List<Webtoon> allWebtoons = webtoonRepository.findAll();
int userIndex = allUsers.indexOf(loginUser);
// 추천 대상 유저와 각 유저들간의 코사인 유사도 계산
double[] combinedSimilarities = similarityCalculator.getCombinedConsineSimilarity(allUsers, allWebtoons,
userEvaluations, userIndex);
return findKNearestNeighbors(combinedSimilarities, K);
}
- 로그인 한 유저와 모든 유저들간의 유사도를 구해야하기 때문에 유저 데이터 전체를 조회한다.
코사인 유사도 구하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public double[] getCombinedConsineSimilarity(List<Account> allUsers, List<Webtoon> allWebtoons,
List<Evaluation> userEvaluations, int userIndex) {
double[][] userVectors = allUsers.stream()
.map(this::preprocessUserData)
.toArray(double[][]::new);
double[][] ratingVectors = allUsers.stream()
.map(user -> getUserRatingVector(allWebtoons, userEvaluations))
.toArray(double[][]::new);
// 추천 대상 유저와 각 유저들간의 코사인 유사도 계산
double[] combinedSimilarities = new double[allUsers.size()];
for (int i = 0; i < allUsers.size(); i++) {
combinedSimilarities[i] = calculateCombinedCosineSimilarity(userVectors, ratingVectors,
userIndex, i);
}
return combinedSimilarities;
}
- 코사인 유사도를 구하기 위해 필요한 데이터를 벡터화한다.
- UserVector, RatingVector이 존재한다.
- 추천 로직 시나리오에서 User 정보에 대한 유사도와 웹툰 평가에 대한 유사도를 따로 구한다고 했으므로 두 개의 벡터가 필요하다.
- 해당 벡터들을 이용해 코사인 유사도를 구한 후 각각 가중치를 주어 합쳐진 하나의 코사인 유사도를 계산해 반환한다.
- preprocessUserData
- 성별, 나이, MBTI 데이터에 대하여 어떠한 수치를 부여해야 한다.
- 예를 들면 성별은 남자 0, 여자 1
- MBTI는 TJ -> 0.2 이런 방식으로 데이터를 수치화 해야한다.
- 참고로 User데이터는 성별, MBTI, 나이의 가중치가 각각 3:5:2로 구성되어 있다.
- 다른 정보의 유사도보다 MBTI의 유사도가 더 높은 경우를 더 유사하다고 본 것이다.
- getUserRatingVector
- 유저의 평가 데이터를 벡터화한다.
- 벡터화는 double[]을 반환하며, index의 값에는 평가 점수가 들어간다.
1
2
3
4
5
6
7
8
9
private double cosineSimilarity(double[] vectorA, double[] vectorB) {
RealVector vector1 = new ArrayRealVector(vectorA);
RealVector vector2 = new ArrayRealVector(vectorB);
double dotProduct = vector1.dotProduct(vector2);
double normalization = vector1.getNorm() * vector2.getNorm();
return normalization == 0 ? 0 : (dotProduct / normalization);
}
- apache.commons.math3을 사용한다.
- RealVector
- 다차원 벡터를 나타내는데 사용된다.
- 벡터의 기본적인 연산들을 지원하도록 되어있고, 벡터의 합, 차, 내적 등을 계산할 수 있다.
- ArrayRealVector
- 배열을 사용해 벡터를 구현할 수 있도록 하는 클래스
- 배열의 인덱스를 사용해 각 요소에 접근한다.
- dotProduct()
- 두 벡터 사이의 내적을 계산한다.
- getNorm()
- 벡터의 노름(norm)을 계산한다. (벡터의 길이)
- return
- 코사인 유사도는 두 벡터의 내적을 두 벡터의 크기의 곱으로 나눈 값이다.
이러한 구조로 코사인유사도를 구하고, 이 코사인 유사도를 이용해 비슷한 이웃 K명을 구하게 된다.
KNN 이웃 구하기
1
2
3
4
5
6
7
8
private int[] findKNearestNeighbors(double[] similarities, int K) {
return IntStream.range(0, similarities.length)
.boxed()
.sorted((i, j) -> Double.compare(similarities[j], similarities[i]))
.limit(K)
.mapToInt(i -> i)
.toArray();
}
- 제공되는 similarities는 combinedSimilarities이다.
- 대상 유저와 각 유저들 사이의 코사인 유사도가 담긴 배열이다.
- 이웃을 구하는 로직은 단순하게 구현했다.
- 유사도를 내림차순으로 정렬해 유사도가 높은 순서대로 K만큼 추출한다.
- K만큼의 대상의 index를 반환한다.
이 index를 이용하여 실제 이웃의 AccountId를 구하고 그 AccountId를 이용해 해당 유저(이웃)의 평가데이터를 이용하게 된다.
추천 결과 구하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
private Set<Webtoon> getNeighborRecommendedWebtoons(Long[] neighborsIds, List<Evaluation> userEvaluations,
int recommendationCount) {
Map<Webtoon, Integer> webtoonFrequency = new HashMap<>();
for (Long neighborId : neighborsIds) {
List<Evaluation> neighborEvaluations = evaluationRepository.findByAccountId(neighborId);
filterHighRatedWebtoons(neighborEvaluations, webtoonFrequency);
}
Set<Webtoon> ratedWebtoons = userEvaluations.stream()
.map(Evaluation::getWebtoon)
.collect(Collectors.toSet());
return getRecommendationExcludingEvaluated(recommendationCount,
webtoonFrequency, ratedWebtoons);
}
- 이웃이 평가한 웹툰 중 평가 점수가 높은 웹툰들의 빈도 수를 구한다.
- 이 때 유저가 평균적으로 주는 점수가 짜거나, 높은 경우가 있을 수 있으므로 평가가 높다는 기준은 유저의 평균 평가 점수에서 웹툰의 평가 점수를 뺐을 때 1점이 넘는 경우를 기준으로 삼는다.
데이터가 덜 쌓인 경우, 그리고 이미 평가한 웹툰을 제거하는 과정에서 추천 결과의 개수가 지정한 만큼 나오지 않기도 한다.
이 부분은 MBTI 조합 뒷자리의 선호 장르를 통해 선호 장르의 랜덤한 웹툰 1~2가지씩을 추출해 추천 결과에 포함시켜 보완하였다.
정리
파이썬으로 추천 알고리즘을 구현했을 땐 찾아볼 자료, 관련 코드 등이 많아 훨씬 수월했던 것 같다.
하지만 해당 추천 알고리즘이 나온지 오래되었고 Java에도 관련 라이브러리들이 많아 자료를 찾아본다면 충분히 알고리즘을 보완할 수 있을 것 같다.
파이썬으로 구현했을 땐 테스트를 할 수 있었는데, Java로 테스트하는 방법을 구현하지 못해 테스트할 수 없었다. 계속해서 방법을 찾아봐야겠다.
우선 Java로 구현한 결과는 데이터가 아직 쌓이지 않아 평가 결과가 불만족스러울 수 있어 MBTI별 선호 장르를 이용해 최대한 보완하였다.
그리고 K값에 따라 성능이 크게 변할 수 있는데, 추후 배포 후 데이터가 쌓이고 추천 결과가 불만족스럽다면 알고리즘 개선 및 K값 수정등의 과정이 필요할 것 같다.