
프로젝트가 성공적으로 마무리 됐고, 최종적으로 선택했던 배포 구조도를 정리해보려 한다.
최종 배포 구조
이번 프로젝트를 진행할 때 AWS에 대한 비용을 지원받을 수 있었기 때문에 개인적으로 프로젝트를 진행할 때 보다 여러가지를 시도해볼 수 있었다.
최종적으로 어떤 아키텍처를 가져갔고, 어떤 점들을 보완해야 하는지 정리해보려고 한다.
서버 아키텍처
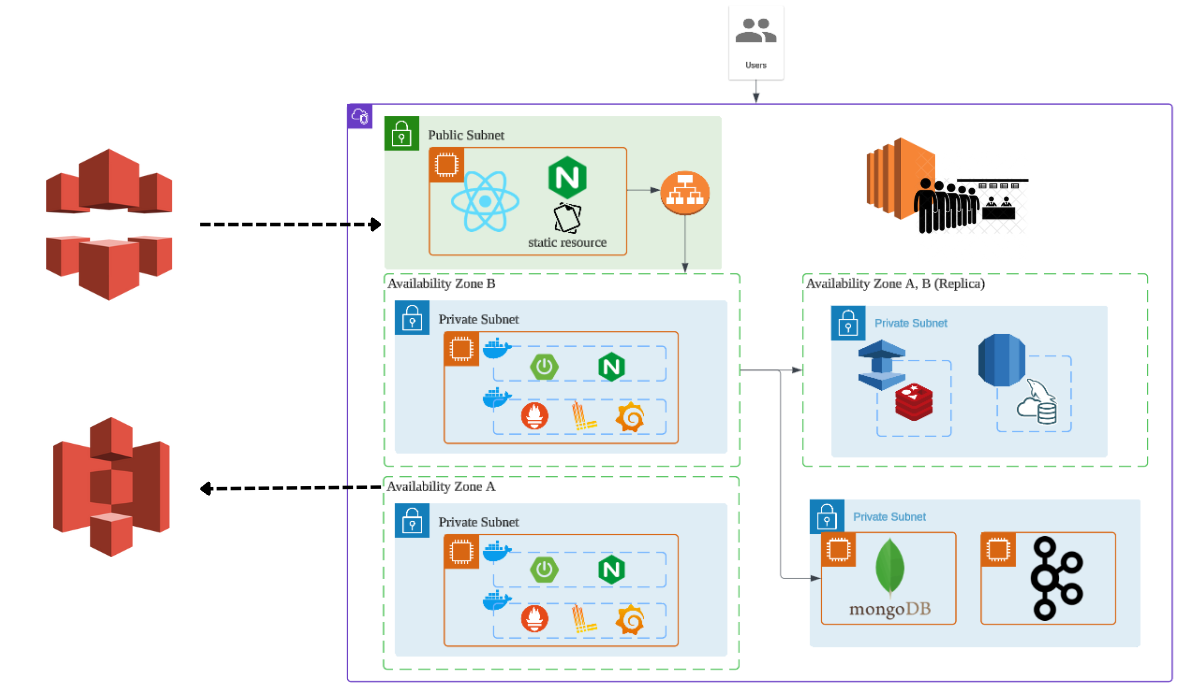
전체 아키텍처는 퍼블릭 서브넷과 프라이빗 서브넷으로 구성된 VPC 내에서 동작하게 된다.
- 로드밸런서, Nginx
- 퍼블릭 서브넷에 배치된 로드밸런서가 트래픽을 처리하게 된다.
- 정적 리소스 요청은 Nginx를 통해 캐싱되어 빠르게 처리되며, API 요청은 백엔드 로드밸런서로 전달되어 분산된다.
- 가용영역(AZ) 분산
- 서비스 중단에 대처하고자 두 개의 가용영역으로 리소스를 분산 배치 했다.
- 백엔드 메인 서버는 각 AZ에 배치되어 로드밸런서가 트래픽을 분산처리하도록 구성했다.
- 데이터베이스 구성
- MySQL (RDS): Primary 노드와 Replica 노드로 구성해 장애에 대비한다.
- Redis (Elasticache): 마찬가지로 Primary 노드와 Replica 노드로 구성해 장애에 대비한다.
- MongoDB, Kafka
- MongoDB와 Kafka는 각각 EC2 인스턴스에 직접 배치해 사용했다.
- CloudFront, AWS S3
- 정적 파일을 빠르게 제공할 수 있도록 CDN, 버킷을 활용한다.
- 모니터링 도구
- Grafana, Loki, Scouter 등을 메인 서버에 함께 구성해 서버의 상태와 애플리케이션 로그를 모니터링한다.
장점 및 보완해야 할 부분
막바지에 발견되는 버그들을 수정하다보니 정해진 시간 내에 완벽한 환경을 구축하기는 힘들었다.
그 당시에는 최선이라고 생각했지만, 돌아봤을 때 어떤 부분이 아쉬울 수 있는지 정리해보고자 한다.
- 장점
- 다중 AZ 분산과 Replica 노드를 활용해 장애에 대비할 수 있었다.
- 대기열을 위한 서버를 분리하면서 일종의 MSA 아키텍처 구조를 가질 수 있었다.
- 확장성 및 유연성에서 장점을 가진다.
- 독립적으로 개발하고 확장할 수 있다.
- 보완점
- 메인 서버에 t3.medium 인스턴스를 사용하고 나머지는 t2.micro로 구성했는데, 실제로 운영하면서 인스턴스의 사양을 고려해보는 경험이 있었다면 좋았을 것 같다. 하지만 당장 실제 운영하기에는 힘든 서비스이기 때문에 아쉬웠다.
- MongoDB와 Kafka가 단일 EC2 인스턴스에서 동작하기 때문에 여기서 장애가 발생한다면 시스템 전체에 영향을 줄 수 있다.
- MongoDB 또한 Replica Set을 구성할 수 있다.
- 추후 안 사실이지만 MongoDB에 Replica Set을 운영하면 트랜잭션을 활용할 수 있다고 한다.
- Kafka 클러스터를 구성해 가용성을 높일 수 있다.
- 여러 개의 브로커를 포함한 클러스터를 구성해 분산 처리를 하고 데이터 손실을 방지할 수 있다.
- 모니터링 도구가 메인 서버에 함께 구축되어 있는데 메인 서버의 리소스를 소비하기 때문에 성능 저하 가능성이 있다.
- 모니터링 전용 서버를 분리하거나 AWS의 CloudWatch를 활용하는 것을 고려할 수 있다.
Kafka 활용의 아쉬움
실제로 Kafka를 운영하다보면 여러 에러들을 많이 만날 수 있다고 한다.
나는 단순하게 개발 단계에서 적용해보고, Kafka를 사용했을 때 어떤 장점을 갖는지 학습하는 정도가 전부였다.
물론 현재 채팅 기능에 주로 Kafka가 적용이 되어 있는데, 최종 구조처럼 메인 서버가 분산됐을 때 Kafka를 도입하지 않으면 WebSocket 서버가 다르기 때문에 문제가 생길 수 있는데 그 부분은 해결할 수 있었다는 점은 좋았다.
하지만 실제로 Kafka를 운영환경에 적용해보면 메시지 유실에 관한 문제, 오프셋 관리 등등 신경쓸 것이 많고 골치아프다고 한다.
Consumer가 메시지를 처리하지 못한 상태에서 커밋이 되면 데이터가 손실되거나 혹은 어떤 상황에서는 메시지가 중복된다거나 하는 문제가 생길 수 있는 것이다.
Kafka를 도입 후 저런 경험을 하고 대응할 수 있는 경험이 있었다면 더 좋았겠다는 아쉬움이 있다.
CI/CD 파이프라인
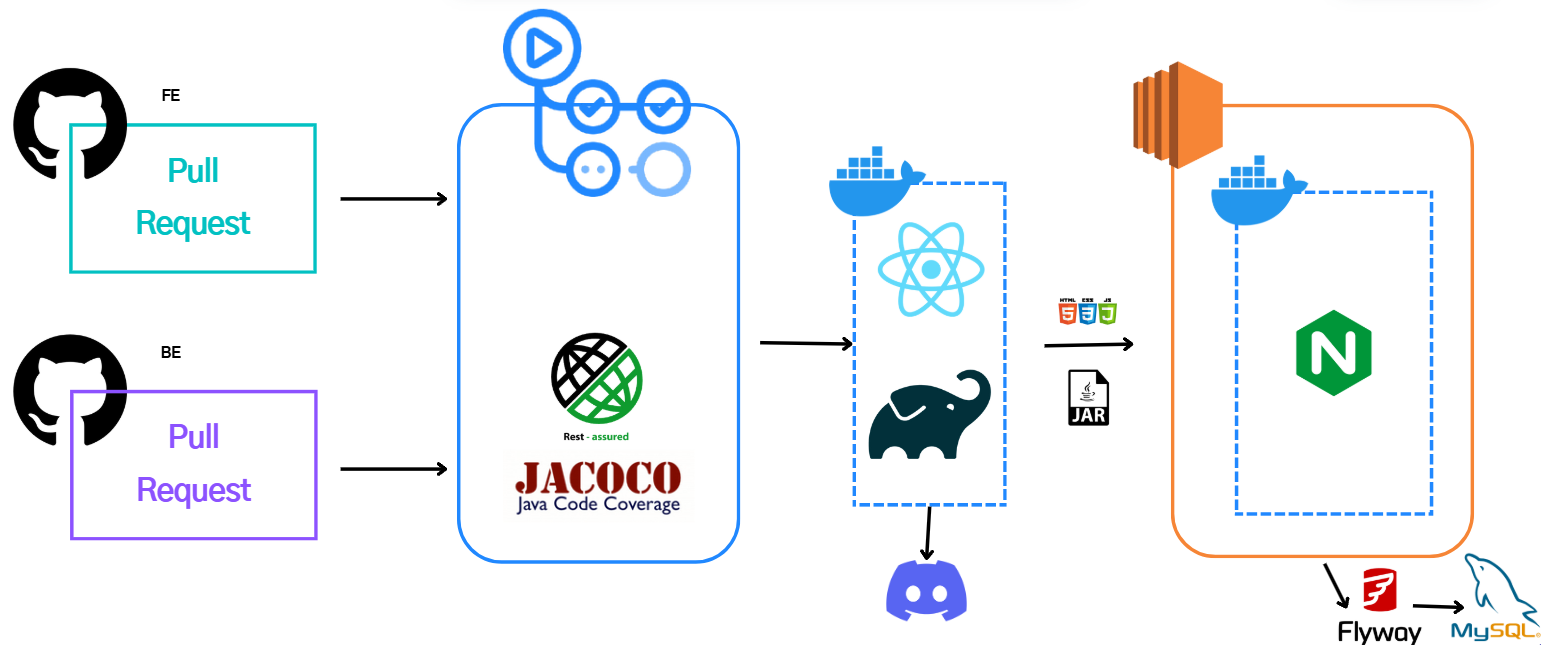
서버 아키텍처의 배포는 위와 같은 구조로 이루어졌다. GithubActions와 Docker를 활용해 자동화했다.
- Pull Request 트리거
- Github에서 Pull Request가 생성되면 CI/CD 파이프라인이 실행된다.
- 프론트엔드 빌드 및 배포
- React 애플리케이션은 정적 리소스로 빌드되어 Nginx를 통해 제공된다.
- 백엔드 컨테이너 배포
- Spring 서버는 Docker 컨테이너로 패키징되어 분산된 서버에 모두 배포된다.
- 배포 상태 모니터링
- 배포 상태는 Discord 알림을 통해 실시간으로 팀원들에게 공유되어 Deploy 과정에 문제가 생겼을 시 즉시 대응한다.
- 마이그레이션
- Flyway를 사용해 MySQL 스키마와 데이터를 자동으로 마이그레이션한다.
보완점
- 무중단 배포를 도입해볼 수 있었으면 좋았을 것 같다.
- 배포 후 문제가 생겼을 때 이전 상태로 빠르게 되돌릴 수 있는 일종의 롤백 부분이 없다.
- CI/CD 파이프라인에 롤백 스크립트를 추가하거나 Docker 이미지를 버전별로 관리하는 방법으로 보완할 수 있다.
- 환경 변수 관리를 Docker Compose를 통해 했었는데 AWS Parameter Store 같은 도구를 활용했ㄷ면 더 편리하고 보안성있는 관리가 됐을 것 같다.
- 배포 이후 응답 시간이나 에러율에 대한 모니터링 알림을 설정하지 않은 것이 아쉽다.
- 실제 운영을 적극적으로 하는 환경이라면 도입했겠지만, 실제로 그렇지 못해서 미처 신경쓰지 못했다.
정리
의도치않게 이번 프로젝트에서 배포 및 환경 구축에 대해 프론트 서버, 백엔드 서버 모두 담당하게 되었다.
AWS를 사용한 경험이 크게 없었기 때문에 학습에 사용된 시간도 꽤 길었고, 여러 장애도 겪었다.
특히 Kafka를 적용할 때 가장 시간을 많이 썼던 것 같다.
Amazon MSK라는 것을 사용해 환경을 구축하려 했는데, 자료도 별로 없고 간단하게 시작할 수 있는 것 처럼 보이지만 로컬이나 EC2 환경과 다르게 Topic을 자동으로 생성해주지 않아 그 부분에서 애를 먹었다.
물론 단순하게 명령어로 Topic을 생성해주면 되지만 MSK 환경에서 명령어를 입력하는 부분에서 애를 먹었었다. 시간이 없었기 때문에 조금 더 익숙하게 환경을 구축할 수 있었던 EC2로 채택하게 되었는데 이 부분도 아쉽다.
그리고 프론트 친구들과 협업하면서 개발 환경 세팅에 대한 중요성도 깨달았다. 다른 부분들은 비교적 쉽게 설치가 가능하고 세팅이 가능해서 로컬 개발에 문제가 없었지만, Kafka는 백엔드 취준생들도 대부분 겉핥기식으로 경험해보는 정도가 다인데다 익숙하지 않기 때문에 환경을 구축하는데 애를 먹었다.
기존 기능에 Kafka를 도입하는 부분이 프로젝트 막바지에 있던 일이라 프론트 친구들은 로컬에 환경을 구축하지 않고 바로 운영환경에 도입하며 개발이 조금 불편했던 경험을 했다.
왜 도커를 사용하지 않았는지, 또는 로컬 개발 환경에서 도커를 활용해 Kafka를 구축하지 않았는지에 대한 후회가 들었다. 도커를 사용했다면 프론트 친구들이 로컬에서 쉽게 환경을 설정하고 테스트할 수 있었을텐데 결국 운영환경에서만 테스트가 가능해져 개발 과정에서 불편함이 컸던 점이 아쉬웠다.