
Kafka 도입
STOMP를 도입했을 때 WebSocket을 활용하여 직접 구현한 방식보다 성능이 좋지 않았다.
따라서 외부 메시지 브로커를 도입하고자 한다.
예전에 사용해보았던 Kafka를 채택하려고 한다. Kafka를 썼을 때 아래와 같은 문제가 해결된다.
SimpleBroker는 인메모리에 메세지를 저장하고 있으므로, 서버가 다운될 경우 처리되지 못한 메세지 요청들이 모두 유실된다. 그래서 Kafka를 도입해 백엔드 서버와 별개로 띄운 후, 메세지 유실을 방지하고 대용량 데이터 처리에도 강점이 있게 구현할 수 있다.
- A유저가 Server1에 웹소켓을 연동하고 /topic/A를 구독
- B유저가 Server2에 웹소켓을 연동하고 /topic/B를 구독
- Server2에 서버에 요청이와서 /topic/A를 구독하는 사람에게 메시지 전송!
- Server2의 in-memory message broker는 A유저가 /topic/A를 구독한다는 정보를 전혀 알지 못해서 A에게 메시지를 전달할 수 없음.
이 문제들을 카프카를 통해 아래와 같은 방향으로 해결이 가능하다.
- A유저가 Server1에 웹소켓을 연동하고 /topic/A를 구독
- B유저가 Server2에 웹소켓을 연동하고 /topic/B를 구독
- 서버에 요청이 오면 Kafka로 해당 메시지 Produce
- Server1, Server2는 해당 메시지를 Consume 대기
- kafka Consumer가 토픽을 구독하여 In-memory Message Broker를 통해 메시지 발송
- 2대의 서버에서 /topic/A를 구독하는 상대에게 모두 메시지가 발송되기 때문에 동기화 문제가 해결.
단 지금 알아두어야 할 것은 내장 브로커를 사용하지 않는 것은 아니다. 구독 처리와 메시지 브로드캐스팅 자체는 내장 기본 브로커가 처리한다.
다만 오는 메시지들을 카프카를 통해 받고 카프카가 그 메시지들을 처리해서 최종적으로는 내장 브로커가 브로드캐스팅하는 구조이다.
대용량의 메시지 처리가 가능하고, 서버 확장에서의 장점을 가진다.
Kafka 도입 구현
카프카 설정을 위한 의존성 추가 및 properties 설정은 생략한다.
KafkaTopicConfig
1
2
3
4
5
6
7
8
9
10
11
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic chatTopic() {
return TopicBuilder.name("chat-topic")
.partitions(3)
.replicas(1)
.build();
}
}
- Kafka 브로커에 새로운 토픽을 생성한다.
- chat-topic 이름을 가진 토픽을 생성하고, 3개의 파티션, 복제본 1개를 설정한다.
- 파티션이 늘어나면 데이터가 여러 노드로 분산되어 처리량이 증가될 수 있다.
- 복제본을 1로 설정하면 하나의 리더 파티션만 사용한다.
- 단일 브로커 환경에서는 복제본을 설정할 수 없어 1로 설정해야 하고, 다중 브로커 환경에서 복제본 수를 늘릴 수 있다.
- 하나의 브로커가 다운되어도 데이터가 유실되지 않을 수 있다.
KafkaProducer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Slf4j
@Service
@RequiredArgsConstructor
public class KafkaChatMessageProducer {
private final KafkaTemplate<String, ChatMessageDto> kafkaTemplate;
public void sendMessage(String topic, ChatMessageDto message) {
kafkaTemplate.send(topic, message)
.whenComplete((result, ex) -> {
if (ex != null) {
log.error("topic {}에 메시지 전달 실패: {}", topic, ex.getMessage(), ex);
} else {
log.info("topic {}에 메시지 전달 성공: {}", topic, message);
}
});
}
}
- 카프카를 통해 메시지를 전송하는 역할을 해주는 클래스이다.
- kafkaTemplate을 사용해 메시지를 특정 토픽에 비동기적으로 전송한다.
- kafkaTemplate.send()
- 메시지를 비동기적으로 해당 토픽에 전송한다.
- 토픽에 메시지가 전송되면 아래 구현할 Consumer에서 처리하게 된다.
KafkaConsumer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Slf4j
@Component
@RequiredArgsConstructor
public class KafkaChatMessageConsumer {
private final ChatService chatService;
private final SimpMessageSendingOperations messageTemplate;
@KafkaListener(topics = "chat-topic", groupId = "chat-group")
public void consumeMessage(ChatMessageDto message) {
log.info("Kafka에서 받은 메시지: {}", message);
chatService.createAndSaveMessage(message);
String destination = "/sub/chat/" + message.getRoomId();
messageTemplate.convertAndSend(destination, message);
log.info("STOMP 브로드캐스트 완료: destination= {}, message= {}", destination, message);
}
}
- 받은 메시지를 처리하고, STOMP를 통해 클라이언트에 브로드캐스트 한다.
- Producer를 통해 전송한 메시지, 즉 chat-topic으로 메시지가 오면 해당 메시지를 처리한다.
- SimpMessageSendingOperations 인터페이스를 이용해 특정 destination으로 메시지를 브로드캐스트한다.
ChatController
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Slf4j
@Controller
@RequiredArgsConstructor
public class ChatController {
private final KafkaChatMessageProducer kafkaProducer;
@MessageMapping("/chat/send/{roomId}") //클라이언트가 이 경로로 메시지를 전송한다.
public void sendMessage(@DestinationVariable Long roomId, @Payload ChatMessageDto message,
SimpMessageHeaderAccessor headerAccessor) {
log.info("message= " + message);
Authentication auth = (Authentication) headerAccessor.getUser();
CustomOAuth2User user = (CustomOAuth2User) auth.getPrincipal();
Long senderId = user.getUserId();
String senderRole = user.getRole();
message.updateSenderInfo(roomId, senderId, senderRole);
kafkaProducer.sendMessage(KafkaTopic.CHAT_TOPIC.getTopic(), message);
}
}
- 이제 SendTo를 사용하지 않아도 된다.
- 메시지 브로드 캐스트를 위에서 보다시피 카프카와 그 컨슈머가 하고 있다.
- 따라서 내장 브로커를 직접 사용하지 않기 때문에 필요가 없다.
- WebSocket 컨트롤러로 WebSocket 서버에서 메시지가 SEND되면 위에서 작성한 kafkaProducer를 이용해 해당 메시지를 카프카 메시지로 보낸다.
성능 테스트
카프카 도입은 위와 같이 구현했을 때 이제 메시지 처리를 내장 브로커로 직접 하지 않고, 카프카를 통해 처리하게 된다.
이제 성능 테스트를 해보자.
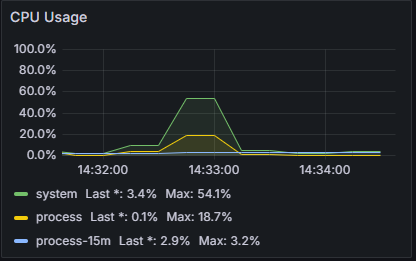
V1
- users: 500
- seconds: 10
- loop: 50

V2
- users: 1000
- seconds: 30
- loop: 50

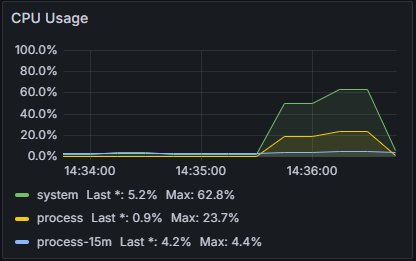
V3
테스트 시나리오를 잘못짠 것 같다.
카프카를 도입한다고 해서 WebSocket 연결 성능에 영향을 미치는 것이 아니다.
연결이 많아지는 것 보다는 다량의 메시지를 처리할 수 있도록 바뀌었는지가 더 중요한 지표이다.
그런데 현재 메시지 처리량을 높이면서 테스트를 하고 있는 것은 맞지만, 메시지 처리량의 수보다 연결 부분에서 이미 에러가 나고, 처리가 제대로 안되고 있기 때문에 성능을 확인할 수 있는 메시지의 양만큼 테스트가 제대로 되고 있지 않다.
- 연결 성능을 높이려면 어떻게 해야할까?
- 내장 브로커는 현재 연결뿐아니라 구독 관리 및 메시지 전달을 해주고 있다.
- RabbitMQ를 내장 브로커대신 사용하면 WebSocket 서버는 연결 유지에만 집중하고 그렇게 되면 서버의 CPU, 메모리 사용량이 감소하게 된다.
- 구독 관리와 메시지 전달과 관련된 부분을 RabbitMQ에서 관리하므로 WebSocket 서버의 부담이 줄어든다.
- RabbitMQ는 STOMP 프로토콜을 지원해주지만 Kafka는 크게 그런 기능이 존재하지 않아 Redis + Kafka를 통한 구독 관리 등을 직접 구현해줘야 한다는 단점이 있다.
결론적으로 내장 브로커의 대체로 RabbitMQ를 사용해 RabbitMQ가 구독을 관리하고, 메시지를 구독자들에게 전달하는 부분을 담당한다.
그리고 Kafka는 그대로 메시지 자체를 처리하여 대량의 메시지 전송을 담당해 WebSocket의 연결 성능을 최대로 높여보고자 한다.
V4
테스트 시나리오를 바꿨다.
연결을 유지하고 채팅을 여러 번 보내는 것으로 수정했다.
WhileController를 사용해 시도했다.
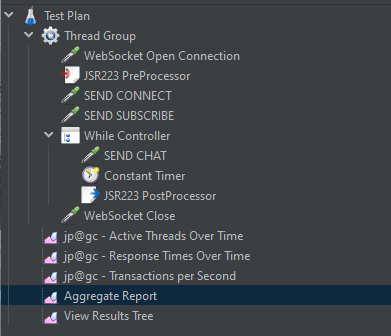
- PreProcessor를 통해 WhileController에서 사용할 값을 초기화해준다.
- WhileController에서는 초기화한 MessageCount라는 값을 사용해 SEND CHAT을 몇 번 호출할 지 정한다.
- PostProcessor를 통해 메시지를 한 번 보낼때마다 MessageCount를 1씩 증가시킨다.
테스트를 2가지 진행해보았다.
- users: 3000
- seconds: 30
- loop: 1 (이제 whileController로 메시지 전송을 처리하기 때문에 3000users에서 연결을 1번 하는 것으로 수정)
- 메시지 100개씩 보낸다고 가정.

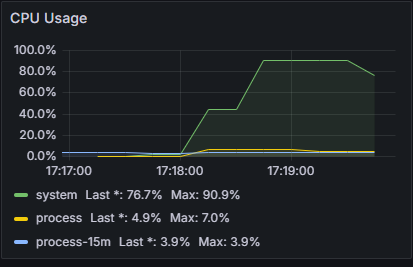
연결은 최대 받아낼 수 있는 것은 현재로서는 3000 users가 최대인 것 같다. 나머지도 어떻게든 돌아가게는 할 수 있지만 제대로 된 동작이 나오지 않는다.
이제 다시 카프카를 적용하기 전을 테스트 해보자.
카프카 적용 전 테스트
V1

- users: 3000
- seconds: 30
- loop: 1
제대로 동작하지도 않는다.
카프카 도입 이후 성능이 크게 향상한 것을 볼 수 있다. 대량의 메시지 처리는 훨씬 성능이 좋다는 것을 확인할 수 있다.
V2
어느정도까지 받아낼 수 있는지 조금 낮춰보기로 했다.
- users: 2000
- seconds: 30
- loop: 1

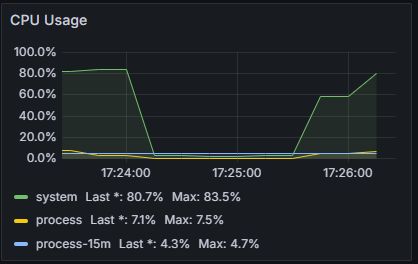
이 정도 수치가 한계인 것 같다.
정리
결과적으로 STOMP 프로토콜에서 카프카를 도입했을 때 훨씬 나은 성능을 보여주는 것을 볼 수 있었다.
여기에 더해 만약 내장 브로커 대신 RabbitMQ로 구독과 메시지 브로드캐스팅의 역할을 담당하도록 변경한다면 더 나은 성능을 보여줄 수 있을 것이다.