
조인 (join)
하나의 테이블이 아닌 두 개 이상의 테이블을 묶어 하나의 결과물을 만드는 것을 말한다.
MySQL에서는 JOIN 쿼리로, MongoDB에서는 lookup 쿼리로 이를 처리한다. 단 MongoDB에서는 lookup은 되도록 지양해야 한다. MongoDB는 조인 연산에 대해 관계형 DB보다 성능이 떨어진다고 여러 벤치마크 테스트에서 알려져 있다.
내부 조인 (inner join)
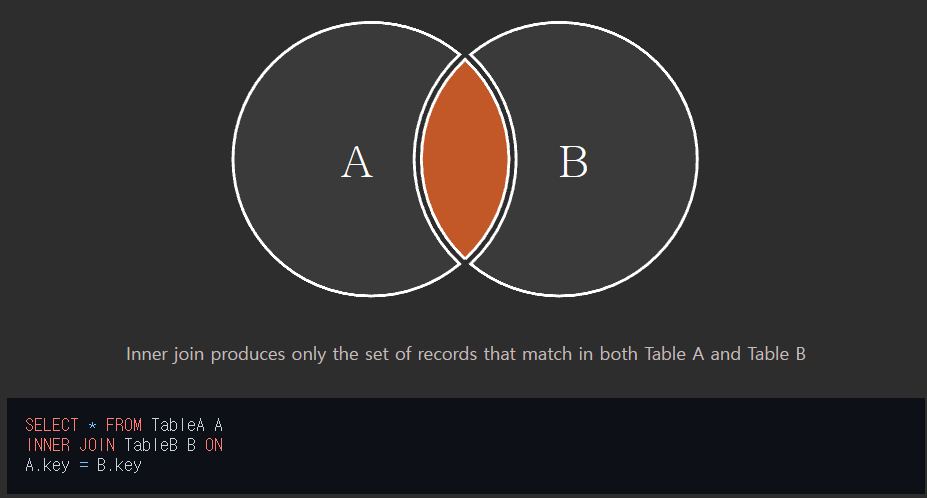
왼쪽 테이블과 오른쪽 테이블의 두 행이 모두 일치하는 행이 있는 부분만 표기한다. 두 테이블의 교집합을 나타낸다.
A테이블의 학번과 B테이블의 학번을 JOIN 했을 때 A 테이블과 B 테이블에 모두 존재하는 학번을 포함하는 행만 추출한다.
ex) 학번 101이 A 테이블과 B 테이블 중 어느 한 곳에라도 존재하지 않는다면 학번 101을 포함하는 행은 추출하지 않는다.
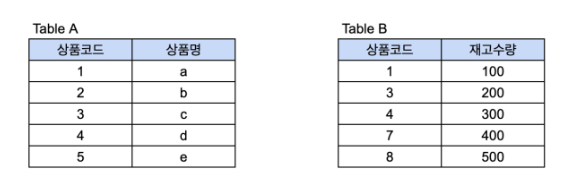
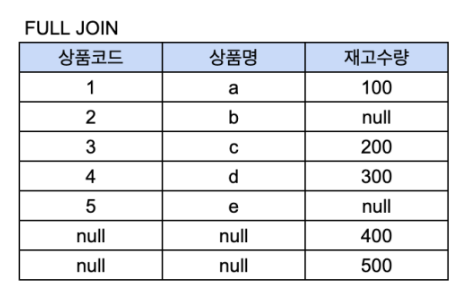
이렇게 테이블이 있고 상품 코드를 조건으로 Inner Join을 하게 되면
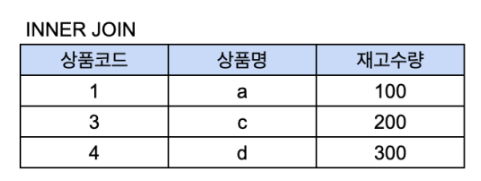
공통으로 상품코드가 있는 1,3,4만 추출되고 각 테이블의 상품명, 재고수량이 합쳐진다.
왼쪽 조인 (left outer join)
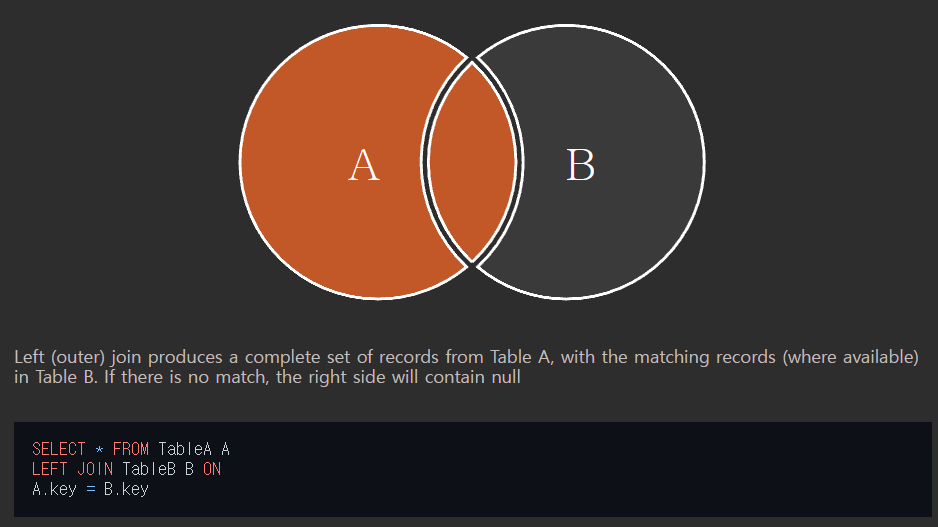
왼쪽 테이블의 모든 행이 결과 테이블에 표기된다. 테이블 B의 일치하는 부분의 레코드와 함께 테이블 A를 기준으로 완전한 레코드 집합을 생성한다.
만약 테이블 B에 일치하는 항목이 없으면 해당 값은 null 값이 된다.
이 테이블들을 상품코드를 조건 (ON A.상품코드 = B.상품코드)으로 걸고 left join을 한다면
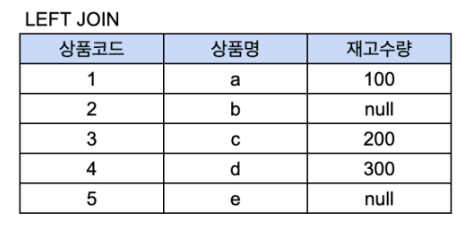
A테이블을 모두 표시하고 B테이블에서 가져오는 재고 수량은 A 테이블의 상품코드와 겹치는 1,3,4만 가져오고 나머지는 null 값을 넣게 된다.
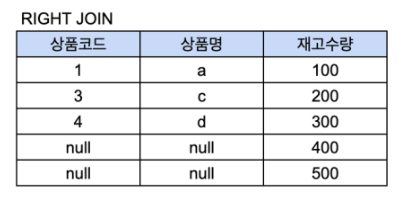
오른쪽 조인 (right outer join)
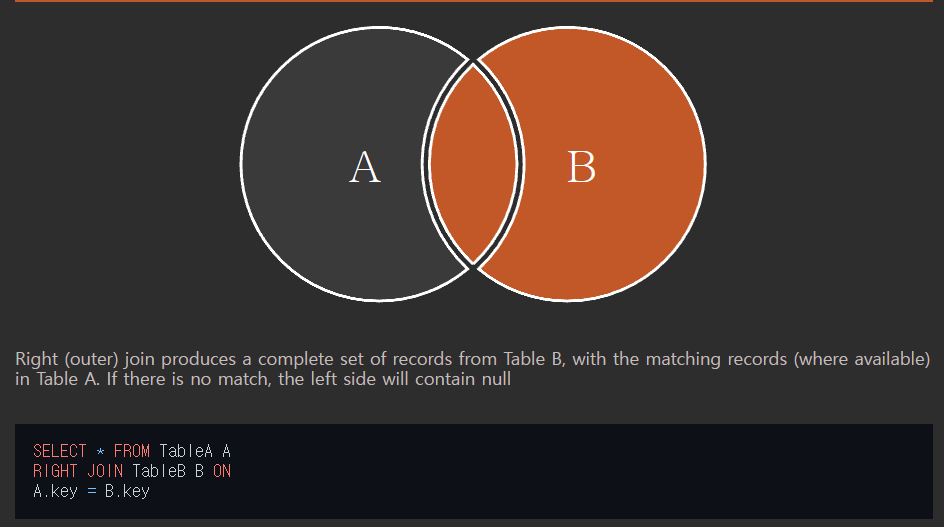
오른쪽 테이블의 모든 행이 결과 테이블에 표기된다. 테이블 A의 일치하는 부분의 레코드와 함께 테이블 B를 기준으로 완전한 레코드 집합을 생성한다.
합집합 조인 (full outer join)
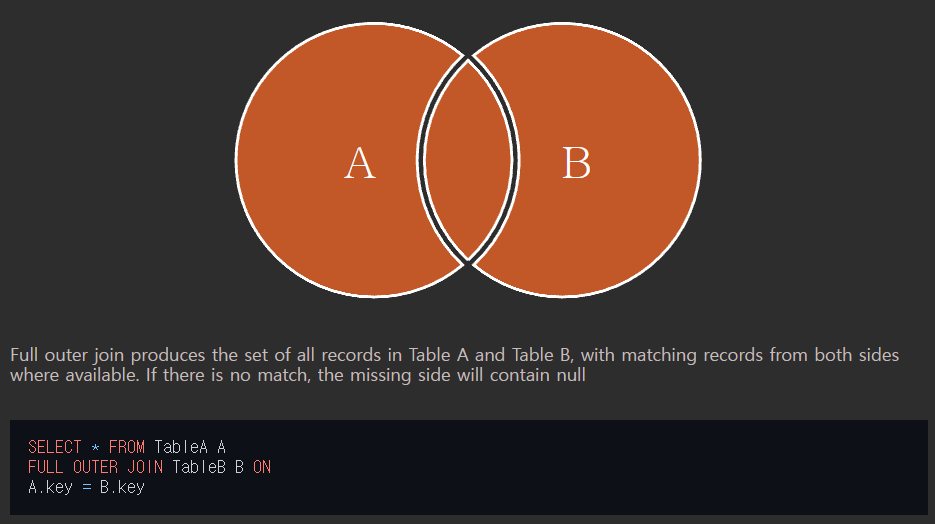
두 개의 테이블을 기반으로 조인 조건에 만족하지 않는 행까지 모두 표기한다.
조인의 원리
앞서 설명한 조인은 조인의 원리를 기반으로 조인 작업이 이루어진다.
조인의 원리는 중첩 루프 조인, 정렬 병합 조인, 해시 조인이 있다. 위의 조인들은 이 원리들을 기반으로 조인을 한다.
중첩 루프 조인 (NLJ, Nested Loop Join)
중첩 for문과 같은 원리로 조건에 맞는 조인을 하는 방법이다.
랜덤 접근에 대한 비용이 많이 증가하므로 대용량의 테이블에서는 사용하지 않는다.
t1, t2 테이블을 조인한다 라고 했을 때 첫 번째 테이블에서 행을 한 번에 하나씩 읽고 그 다음 테이블에서도 행을 하나씩 읽어 조건에 맞는 레코드를 찾아 결과값을 반환한다.
정렬 병합 조인
각각의 테이블을 조인할 필드 기준으로 정렬하고 정렬이 끝난 이후에 조인 작업을 수행하는 조인이다.
조인할 때 쓸 적절한 인덱스가 없을 때, 대용량의 테이블들의 조인, 조인 조건으로 <, > 등 범위 비교 연산자가 있을 때 사용한다.
해시 조인
해시 테이블을 기반으로 조인하는 방법이다.
두 개의 테이블을 조인한다고 했을 때 하나의 테이블이 메모리에 온전히 들어간다면 보통 중첩 루프 조인보다 더 효율적이다. (메모리에 올릴 수 없을 정도로 크다면 디스크를 사용하는 비용이 발생한다.)
동등(=) 조인에서만 사용 가능하다.
해시 조인의 단계
- 빌드 단계
- 입력 테이블 중 하나를 기반으로 매모리 내 해시 테이블을 빌드하는 단계
- persons와 countries라는 테이블을 조인한다고 했을 때 둘 중에 바이트가 더 작은 테이블을 기반으로 테이블을 빌드한다.
- 또한 조인에 사용되는 필드가 해시 테이블의 키로 사용된다.
- ex) countries.country_id
- 프로브 단계
- 레코드 읽기를 시작한다.
- 각 레코드에서 persons.country_id에 일치하는 레코드를 찾아 결과값으로 반환한다.
이를 통해 각 테이블은 한 번씩만 읽게 되어 중첩해서 두 개의 테이블을 읽는 중첩 루프 조인보다 보통은 성능이 더 좋다.
중첩 루프가 아니라 각각 for문을 돌리게 되는 것이다. O(N)
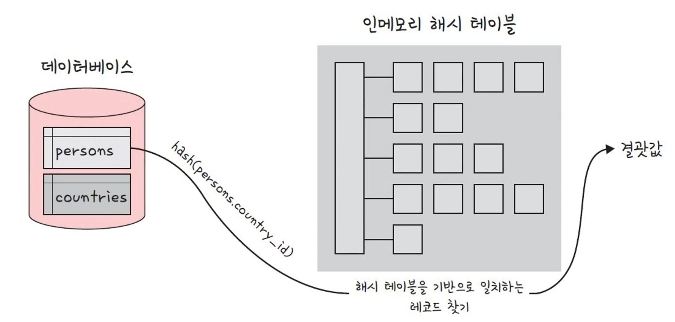
인메모리 해시 테이블은 countries 테이블을 기반으로 작성됨. (바이트가 더 작기 때문)
데이터베이스의 데드락과 해결방법
데이터베이스의 데드락은 데이터베이스의 교착 상태를 말한다.
둘 이상의 트랜잭션이 서로가 잠금을 포기하기를 기다리는 상황인 것이다.
ex) accounts 테이블과 order 테이블이 있다고 가정해보자.
transaction A는 accounts 테이블의 일부 행에 잠금을 건 상태로 이 트랜잭션을 완료하려면 order 테이블의 일부 행을 업데이트 해야한다.
transaction B는 order을 잠금하고 accounts의 데이터 항목이 필요한 것이다.
이렇다면 둘 중 하나를 중단하지 않는 한 서로 기다리기만 하기 때문에 모든 활동이 중단된다.
데드락의 해결
- 교착 상태 감지 및 timeout
- 일정시간(timeout) 이후 트랜잭션이 실행되지 않았을 경우 롤백.
- 그래프 기반 사이클 탐색
- 그래프 내의 사이클이 형성되었다라는 것을 기반으로 교착상태를 감지
- 대규모 DB의 경우 이를 하나하나 감지하기에는 너무나 큰 cost가 발생하기 때문에 교착 상태 방지를 많이 사용하게 된다.
교착 상태 방지
최대한 교착상태가 일어나지 않게 방지한다.
- 격리 수준 변경
- 교착 상태를 방지하기 위해 격리 수준을 행 수준 잠금 또는 격리 수준을 조정하는 것.
- serializable이 아닌 이상 모든 교착상태를 완전히 제거하는 것은 아니다.
- 서비스의 로직을 교차되지 않게 수정
- 서비스의 논리 구조를 바꾸는 것
- accounts -> order 같이 서로 교차되지 않고 일관성있게 바꾸는 방법.
- wait-die 또는 wound wait 방법
- 타임스탬프를 기반으로 트랜잭션을 대기, 선점, 종료하는 방식
- wait-die
- ex) 트랜잭션 T5, T10, T15가 있다고 가정한다.
- 각각 타임스탬프 5, 10, 15의 값을 갖는다.
- T5가 T10이 보유한 데이터 항목을 요청하면 T5는 대기한다.
- T15가 T10이 보유한 데이터 항목을 요청하면 T15는 죽는다.
- 즉 오래된 것이 우선.
- wound wait
- ex) 트랜잭션 T5, T10, T15 있다고 가정한다.
- T5가 T10이 보유한 데이터 항목을 요청하면 데이터 항목이 T10에서 선점되고 T10이 일시 중단된다.
- T15가 T10이 보유한 데이터 항목을 요청하면 T15는 대기한다.
둘 다 타임스탬프를 기반으로 오래된 것이 우선된다.