
현재 유플러스 유레카 과정을 수료중에 있다. 교육을 받으면서 팀 프로젝트를 진행했는데 프로젝트가 끝나고 추가적으로 기능을 구현하면서 그동안 써보지 않았던 기능, 그리고 사용은 했었지만 따로 정리하지 않았던 기능들에 대해 정리하고자 한다.
기존 진행
우선 현재 어떤 프로젝트를 했고, 어떤 기능을 구현하다가 이 글을 정리하게 되었는지 간단하게 설명하고 정리하고 싶은 부분을 서술할 것이다.
과정 중 처음으로 진행하는 팀 프로젝트였고 시간도 1주일정도만 주어진 작은 프로젝트였기 때문에 재밌게 할 수 있을만한 프로젝트를 선정했다.
백엔드 비대면 과정이라 서로 얼굴정도만 알고 같은 조가 되지 못한 사람들은 자세히 알지 못한다. 그래도 각자 자기소개서를 올리는 시간을 가졌었고 그 데이터를 바탕으로 프로젝트를 진행하면 재밌겠다고 생각해 유레카 정보 관리 시스템을 제작하게 되었다.
- 기능
- 회원가입, 로그인
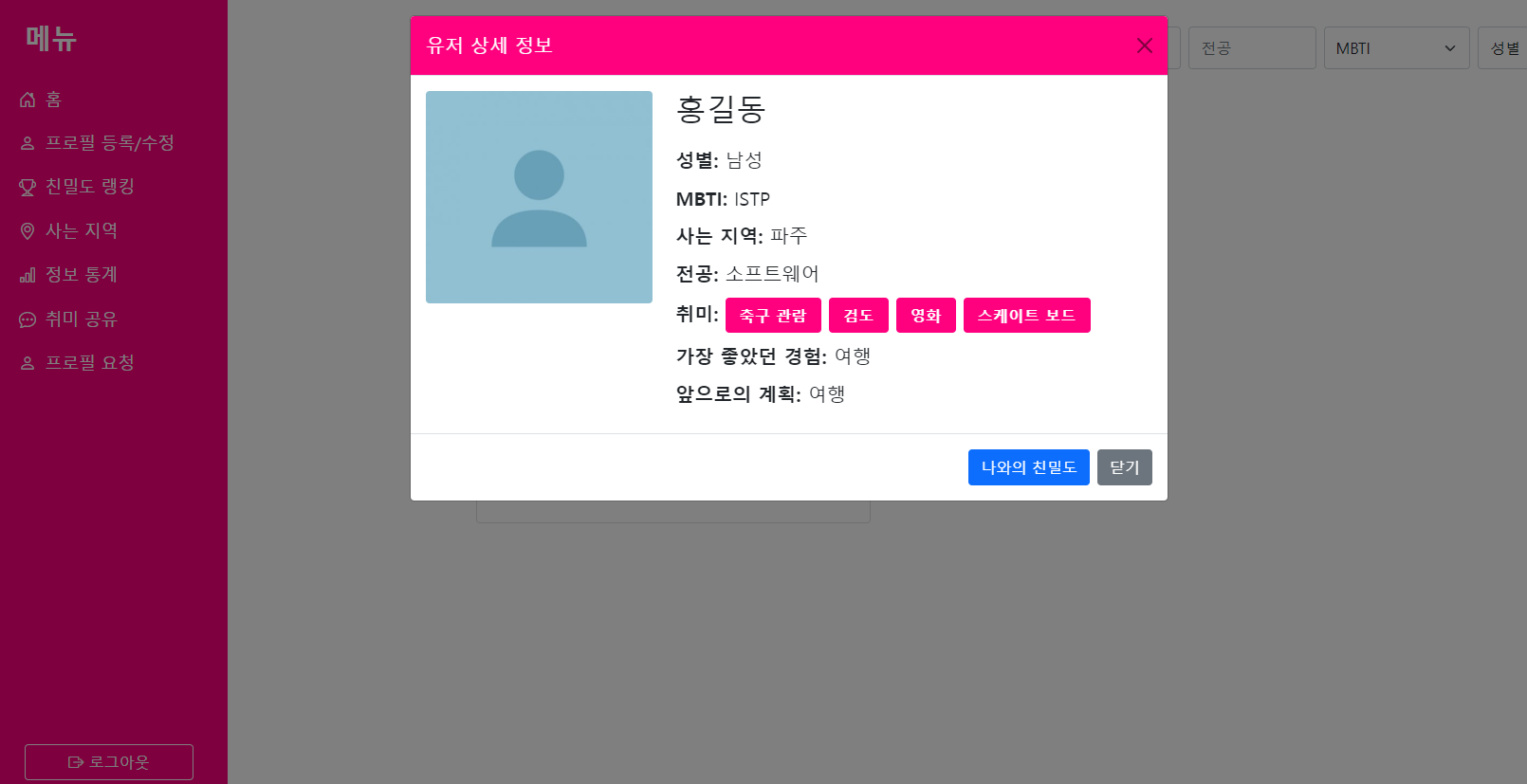
- 프로필 조회
- 이름, 성별, MBTI, 전공을 검색어로 필터링해 조회할 수 있다.
- 동적 쿼리 사용.
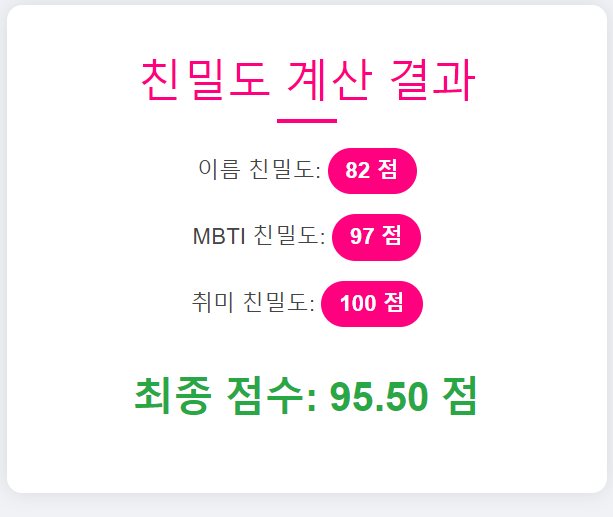
- 유저간 친밀도 조회
- 이름 획 수 점수
- MBTI 궁합 점수
- 취미 궁합 점수
- 3가지의 점수를 계산하고 각 가중치를 다르게 두어 최종 친밀도 점수를 구하게 된다.
- 프로필 등록/수정 요청
- 프로필 등록/수정 요청 관리
- 유저가 프로필을 등록/수정 요청하면 관리자가 해당 프로필을 보고 승인/거부를 한다.
- 대부분의 기능이 프로필을 바탕으로 하는데 승인된 프로필에 한정된다.
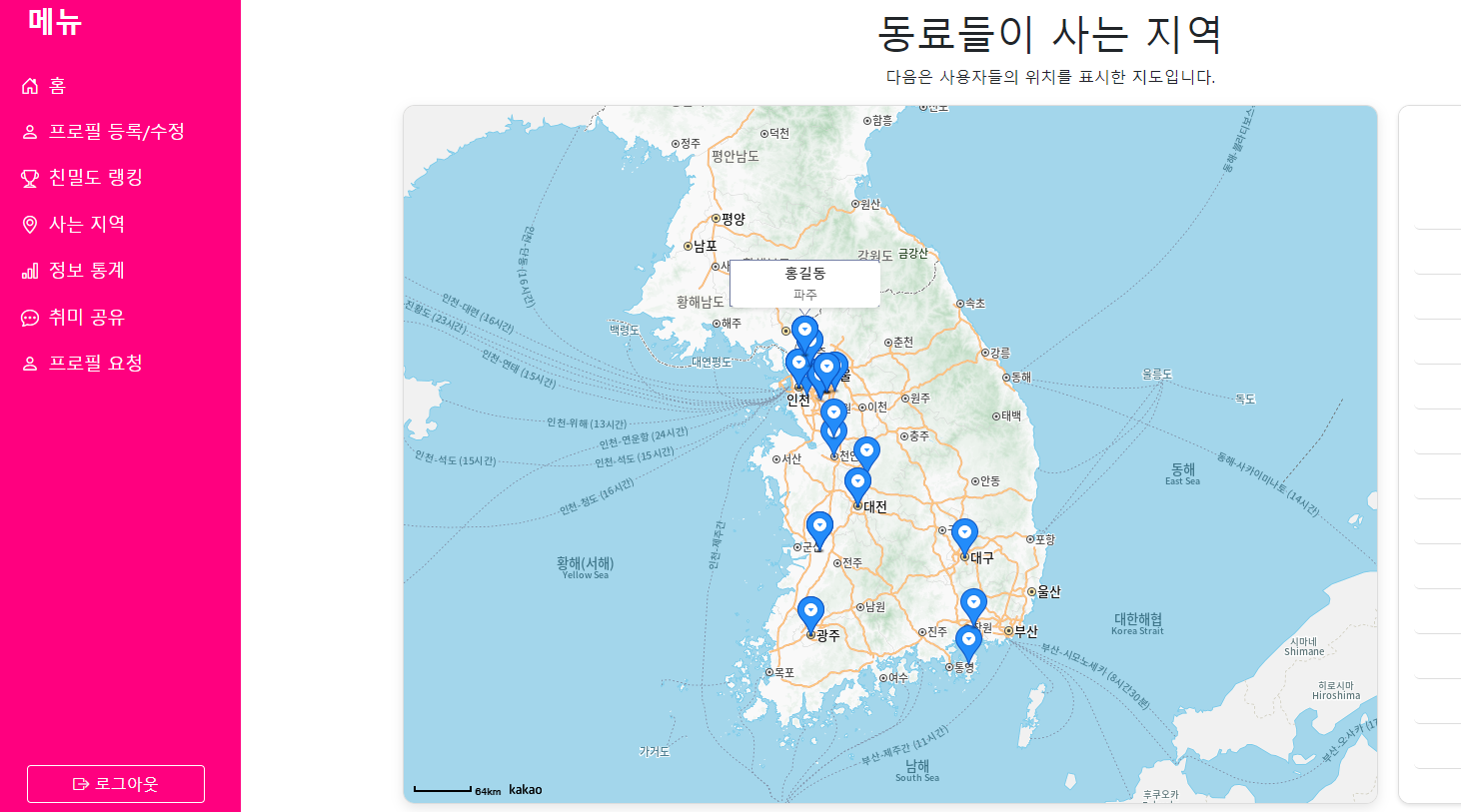
- 지도 메뉴
- 카카오맵 API를 이용해 각자 사는 지역을 마커로 찍어주고, 각자 얼마나 멀리 사는 지 알 수 있는 페이지
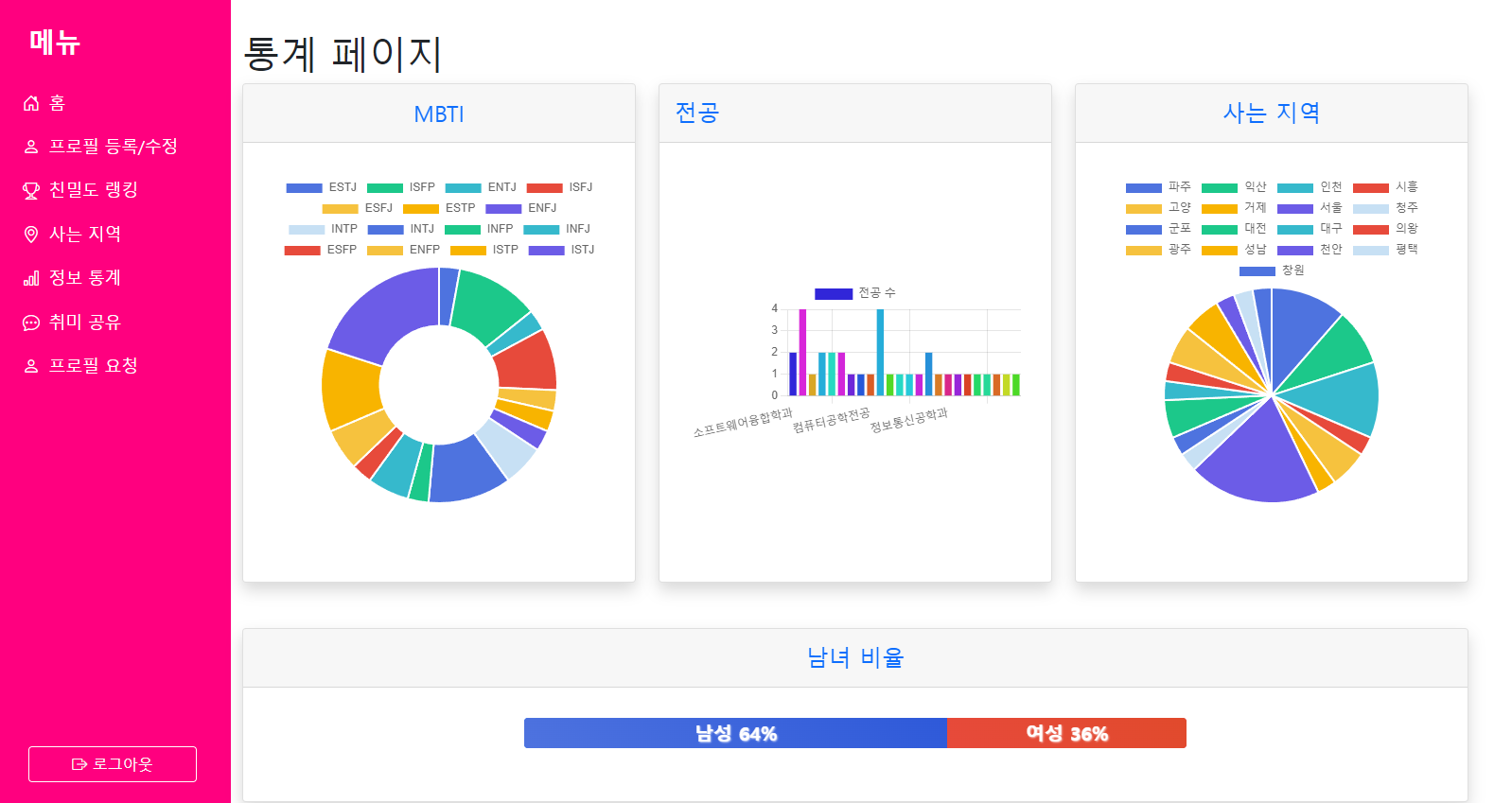
- 통계 메뉴
- 각 프로필에 담긴 정보들을 바탕으로 성별, MBTI, 전공, 취미 등의 통계를 그래프로 확인할 수 있는 페이지
- 취미 공유 게시판
- 각자의 취미를 바탕으로 관련된 유튜브 영상을 공유하고 의견을 나누는 게시판
- CRUD 기능 구현 연습용으로 개발된 기능이다.
이러한 기능들을 각자가 원하는 부분을 맡아 개발하게 되었고 그 중 나는 프로필 조회, 유저 간 친밀도 조회 부분을 맡게 되었다.
구현된 화면 중 일부는 아래와 같다.
새로운 기능 구현
생각보다는 프로젝트가 어느정도는 잘 완성된 것 같아서 기존에 기간안에 구현하지 못한 부분이 아쉬웠다.
그래서 그 기능 정도는 구현하고 마무리하는게 좋을 것 같아 개발을 시작했다.
기존에 구현한 기능으로는 로그인한 유저와 프로필 상세보기를 한 유저간의 친밀도를 계산해서 보여줄 뿐이었는데, 피드백을 받아보니 전체 유저와의 친밀도 랭킹을 원한다는 의견이 있었다.
이 기능은 사실 팀끼리 개발할 당시에도 나왔던 의견이었고 시간안에 구현하지 못하는 상황이었어서 하지 못했었다.
이렇게 단일 페이지로 점수를 확인할 수 있던 부분을 아래와 같이 순위를 확인하는 방식으로 구현하고자 했다.
각 프로필 사진과 순위, 친밀도 점수, 이름을 카드형태로 제공하는 방식을 이용해 친밀도 점수 순위를 나타내었다.
고려했던 부분
친밀도 점수를 계산하는 로직은 그렇게 큰 복잡도가 있는 계산은 아니다. 하지만 유저가 많다고 가정했을 때 매번 새로 계산한다면 (해당 메뉴에 접근한 유저 * 승인된 프로필 수 - 1)만큼 계속 계산되기 때문에 충분히 부하가 있을 수 있다고 판단했고 비효율적이라고 생각했다.
- 따라서 DB에 점수를 미리 계산해두고 조회하는 방식을 채택했다.
- 물론 처음 메뉴에 접근했을 때는 계산된 점수 값들이 없기 때문에 새로 계산하여 DB에 insert하는 부분은 필요했다.
그런데 또 고민인 부분은 매번 메뉴에 접근할 때마다 매번 DB에서 단순 조회를 한다면 그 또한 비효율적인 방법이었다.
따라서 기존에 사용해보았던 Redis를 사용한 캐시 방식으로 조회 시 성능을 개선해보고자 했다. 결과는 아래와 같다.
- 유저가 처음 메뉴에 접근해 전부 새로 계산하는 경우

- 캐시를 이용하지 않고 DB에서 조회할 경우

- 일정 시간 내에 다시 메뉴에 접근해 캐시를 이용하는 경우

결과를 보면 캐시 기능은 성공적으로 개발되었다.
해당 개발 내용에 대해 정리하기 전에 우선 기존에 캐시를 구현해보았지만 Redis의 사용 관련해 정리한 적은 없어 정리해보고자 한다.
Redis
우선 Redis는 메모리에 올려서 사용하는 Key-Value 형태의 DB이다.
메모리 기반이기 때문에 빠르게 읽고 쓸 수 있어 고성능의 캐싱에 주로 사용하게 된다. 메시지 큐나 세션 관리에도 사용된다.
특징을 정리하자면 아래와 같다.
- 메모리 기반 데이터 베이스
- 모든 데이터가 메모리 내에 저장되기 때문에 매우 빠르게 접근할 수 있다.
- 다양한 데이터 구조를 지원한다.
- 단순히 String뿐 아니라 Hash, List, Set 등 다양한 형식을 지원한다.
- 메모리 기반 데이터베이스이지만 데이터를 디스크에 백업할 수 있어 시스템이 재시작되어도 데이터를 유지할 수 있다.
사용
우선 사용을 위해서는 Redis 서버를 설치해주어야 한다.
Spring 환경에서 Redis를 사용하기 위한 부분을 알아보자.
- 의존성 추가
- spring-boot-starter-data-redis 의존성을 추가하면 Redis와 연동할 수 있다.
1
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
- Redis 설정
- 보통 application.properties 또는 application.yml 파일에서 설정한다.
- 로컬일 경우 아래와 같이 설정하게 된다.
1
2
3
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=
- RedisTemplate 사용
- SpringBoot에서 일반적으로 Redis와 상호작용을 하기 위해서는 RedisTemplate을 사용한다.
- 다양한 데이터 타입을 지원하고 Redis에 저장하고 조회하는 기능을 지원한다.
보통 위와 같은 과정을 거쳐서 Redis 사용을 위한 세팅을 마치고 Redis를 사용하게 된다.
그리고 Redis를 사용하기 위한 Config 클래스를 보통 작성하게 되는데 내가 작성한 부분을 보며 해당 코드가 어떤 의미인지 알아보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
@Configuration
@EnableCaching
public class RedisConfig {
@Value(value = "${spring.data.redis.host}")
private String host;
@Value(value = "${spring.data.redis.port}")
private int port;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(host, port);
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory());
template.setDefaultSerializer(new StringRedisSerializer());
return template;
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheConfiguration cacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofMinutes(20))
.disableCachingNullValues();
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(cacheConfig)
.build();
}
}
- @EnableCaching
- SpringBoot에서 캐싱 기능을 활성화하는 역할을 한다.
- 이를 통해 @Cacheable, @CacheEvict와 같은 캐싱 애노테이션을 사용할 수 있도록 한다.
- Redis를 캐시 저장소로 사용할 수 있도록 설정을 활성화하는 역할을 한다.
- @Value
- Redis 설정에서 작성한 application.properties의 정보를 활용해 Redis의 호스트와 포트 값을 가져온다.
- RedisConnectionFactory
- Redis 서버와의 연결을 생성하는 RedisConnectionFactory 객체를 생성한다.
- 위 코드에서 사용한 LettuceConnectionFactory는 Redis 클라이언트 중 하나인 Lettuce를 사용해 Redis 서버에 연결하는 객체이다.
- RedisConnectionFactory는 RedisTemplate 및 CacheManager와 같은 Redis 관련 빈에 주입된다.
- redisTemplate()
- Redis와의 연결을 위해 redisConnectionFactory()를 이용해 연결 설정을 주입받았다.
- template.setDefaultSerializer(new StringRedisSerializer())는 Redis에 데이터를 저장할 때 기본적으로 문자열을 저장하고 읽을 수 있도록 시리얼라이저를 설정하는 역할을 한다.
- 위의 코드로는 키와 값을 문자열로 직렬화하여 저장할 수 있다.
- GenericJackson2JsonRedisSerializer()과 같이 시리얼라이저는 다양하게 존재한다.
- cacheManager()
- SpringBoot의 캐시 관리자를 설정하는 부분이다.
- Redis를 캐시 저장소로 사용하도록 설정한다. Spring의 캐시 기능은 CacheManager 인터페이스를 사용하게 되고, 위와 같이 설정할 경우 RedisCacheManager가 생성된다.
- RedisCacheConfiguration
- 캐시의 기본 설정을 정의한다.
- entryTtl: 각 캐시 항목의 만료 시간을 설정한다.
- disableCachingNullValues(): null값을 캐시하지 않도록 설정한다. DB에서 조회된 값이 null인 경우 해당 결과는 캐시되지 않는다.
- RedisCacheManager
- Redis를 기반으로 한 캐시 관리자를 builder를 통해 생성했다.
- connectionFactory를 사용해 Redis와의 연결을 설정한다.
- cacheDefaults()를 사용해 기본 캐시 설정을 적용한다.
하나 더 설명하자면 Redis는 Pub/Sub 패턴을 지원해 메시지 브로커로도 사용할 수 있다.
애플리케이션 내에서 비동기 메시징 시스템을 구현할 수 있다.
- 메시지 발행
1
2
3
4
5
6
7
8
9
10
@Component
public class RedisPublisher {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
public void publish(String channel, String message) {
redisTemplate.convertAndSend(channel, message);
}
}
- 메시지 구독
1
2
3
4
5
6
7
8
@Component
public class RedisSubscriber {
@EventListener
public void handleMessage(Message message, byte[] pattern) {
System.out.println("Received message: " + message);
}
}
알림 시스템 등을 구현할 때 사용해볼 수 있다.
실제 적용 코드
캐시를 적용할 때 내가 구현했던 코드를 보면서 캐시를 간단히 적용하는 방법 등에 대해 알아보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class FamiliarityService {
public Page<FamiliarityRankingDto> calculateFamiliarityRanking(Long loginUserId, Pageable pageable) {
if (loginUser.getProfile() == null) {
throw new IllegalStateException("프로필 등록이 필요합니다.");
}
List<Profile> allApprovedProfile = profileRepository.findAllAcceptedProfile().stream()
.filter(profile -> !profile.getUser().getId().equals(loginUserId))
.toList();
List<FamiliarityRankingDto> rankingList = allApprovedProfile.stream()
.map(profile -> familiarityRankService.getFamiliarityResult(loginUser, profile))
.sorted(Comparator.comparing(FamiliarityRankingDto::getFinalScore).reversed())
.toList();
int start = (int) pageable.getOffset();
int end = Math.min((start + pageable.getPageSize()), rankingList.size());
List<FamiliarityRankingDto> pagedRankingList = rankingList.subList(start, end);
long total = rankingList.size();
return new PageImpl<>(pagedRankingList, pageable, total);
}
- 우선 승인된 프로필들을 전부 가져온 후 그 각각의 프로필들과 로그인된 유저간의 친밀도 결과를 stream을 통해 가져오도록 하였다.
- .map(profile -> familiarityRankService.getFamiliarityResult(loginUser, profile))
- 기존에는 이 코드가 familiarityService에 같이 포함되어 있었다. 이 방식에는 문제가 있다. 아래에서 설명한다.
- 따라서 서비스 클래스를 분리하고 캐시 기능이 적용된 메서드를 다른 서비스 클래스에 작성하게 되었다.
- 결과적으로는 친밀도 체크 결과를 가져오고 정렬해 페이지 객체로 반환하였다.
- 순위 프로필 카드가 한 페이지 당 9개씩 보여지게 하기 위해 페이지네이션을 적용했다.
캐시를 적용한 서비스 클래스의 코드를 보자.
1
2
3
4
5
6
7
public class FamiliarityRankService {
@Cacheable(value = "familiarityScores", key = "#loginUser.getId() + '-' + #targetProfile.getId()")
public FamiliarityRankingDto getFamiliarityResult(User loginUser, Profile targetProfile) {
return calculateAndSaveFamiliarity(loginUser, targetProfile);
}
}
- 일단 반환하는 값에 대해 설명하면 기존 DB에 계산값이 존재하면 그 값을 조회하고, 값이 존재하지 않는다면 계산해 DB에 값을 insert한 뒤 필요한 데이터를 DTO로 반환한다.
- @Cachable
- Spring의 캐싱 기능을 이 애노테이션을 통해 사용하게 된다.
- 메서드의 결과를 캐시한다. 그리고 동일한 입력값으로 다시 호출될 경우 캐시에서 값을 반환한다.
- value 값을 통해 캐시의 이름을 지정한다.
- key를 통해 캐시의 키를 정의한다.
- “familiarityScores::1-6” 예시로 이렇게 저장이 되고 해당 key를 조회하면 DTO 데이터들이 담겨져 있다.
그리고 사용하진 않았지만 다른 캐시 애노테이션들도 정리해본다.
- @CacheEvict
- 메서드 실행 시 캐시에 저장된 데이터를 삭제한다.
1
2
3
4
@CacheEvict(value = "users", key = "#id")
public void deleteUserById(Long id) {
//...
}
- @CachePut
- 메서드가 실행될 때마다 결과를 캐시에 저장하고, 항상 메서드를 실행한다.
- 메서드를 실행하면서 동시에 캐시를 갱신하고자 할 때 사용된다.
- @Cacheable과의 차이는 항상 메서드를 실행한 후 캐시에 결과를 저장하는 것이다.
- @Cacheable은 이미 캐시되었을 경우 메서드의 실행을 스킵한다.
- @Caching
- 위에 설명했던 캐시 애노테이션들을 조합하여 사용할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
@Caching(
cacheable = {
@Cacheable(value = "users", key = "#id")
},
put = {
@CachePut(value = "users", key = "#result.id")
}
)
public User getUser(Long id) {
//...
return userRepository.findById(id).orElse(null);
}
정리하자면 위에 설명한 캐시 애노테이션과 Redis를 사용해 간단히 캐시를 구현할 수 있었고 친밀도 랭킹을 조회할 때 조금 더 효율적으로 할 수 있었다.
기존 캐시 애노테이션 적용 메서드가 같은 클래스에 있을 때 문제
Spring에서는 @Cacheable과 같은 애노테이션이 있을 때 프록시를 사용하여 메서드 호출을 가로채 캐싱 로직을 적용하도록 되어있다.
이 프록시가 외부에서 해당 메서드를 호출할 때만 작동하도록 되어있는데, 같은 클래스 내부에서 메서드를 호출할 경우 프록시가 동작하지 않아 캐싱이 동작하지 않는 문제가 있었다.
정리
우선 Redis를 사용한 캐싱 방식은 쉽게 구현했고 Redis 사용법에 대해 정리해보았다.
하지만 캐시 기능 구현 후 고려했던 부분을 아직 정리하지 않았다. 다음 포스트에서 어떤 부분을 고려했는지, 그리고 어떤 방식으로 문제를 해결했는지 정리해보겠다.