
이번에는 기존에 작성했던 배치 작업에 대해 개선을 해보려고 한다.
좋아요 누른 도서에 따라 자녀 프로필의 자녀 성향이 바뀌는 작업이다.
나머지 배치 작업은 이번에 도서 조회 쿼리를 개선하면서 생긴 search_text 컬럼을 update 해주는 부분과 성향 히스토리가 논리적으로 1달 전에 삭제되었을 때 물리적 삭제를 진행하는 작업이 있는데 비교적 단순한 작업이기 때문에 자녀 성향 변경 배치작업에 중점을 두고 진행했다.
기존 배치 코드
우선 개선 전 배치 작업 코드를 확인해보자.
Redis에 저장된 좋아요/싫어요 이벤트 데이터들을 읽어와 해당 이벤트 정보를 기반으로 DB에 저장되어있는 성향 점수를 업데이트하고 업데이트된 성향 점수를 바탕으로 성향 히스토리를 생성해 저장하는 작업이다.
작업이 완료되면 Redis에 있는 이벤트 데이터들은 삭제하며 배치 작업이 마무리된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
@Slf4j
@Configuration
@RequiredArgsConstructor
public class ChangePersonalityBatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final RedisUtil redisUtil;
private final ChildProfileService childProfileService;
private final PersonalityScoreService personalityScoreService;
private final ChildPersonalityHistoryService historyService;
private final BookService bookService;
private final MBTIService mbtiService;
@Bean
public Job processLikeDislikeEventsJob() {
return new JobBuilder("processLikeDislikeEventsJob", jobRepository)
.start(processLikeDislikeEventsStep())
.build();
}
@Bean
public Step processLikeDislikeEventsStep() {
return new StepBuilder("processLikeDislikeEventsStep", jobRepository)
.<String, Long>chunk(100, transactionManager)
.reader(redisEventReader())
.processor(eventProcessor())
.writer(eventWriter())
.build();
}
@Bean
@StepScope
public ItemReader<String> redisEventReader() {
List<Object> eventObjects = redisUtil.getAllFromList(BOOK_LIKE_EVENT_LIST.getKey());
log.info(eventObjects.toString());
List<String> events = eventObjects.stream()
.map(Object::toString)
.toList();
return new ListItemReader<>(events);
}
@Bean
public ItemProcessor<String, Long> eventProcessor() {
log.info("processor");
return message -> {
String[] data = message.split(":");
Long childProfileId = Long.parseLong(data[0]);
Long bookId = Long.parseLong(data[1]);
String action = data[2];
ChildProfile childProfile = childProfileService.getChildProfileWithMBTIScore(childProfileId);
Book book = bookService.getBook(bookId);
List<BookMBTI> bookMBTIS = book.getBookMBTIS();
double changedScore = action.equals("LIKE") ? 2.0 : -2.0;
personalityScoreService.updateGenreAndTopicScores(childProfile, book, changedScore);
personalityScoreService.updateCumulativeMBTIScore(childProfileId, bookMBTIS, changedScore);
return childProfileId;
};
}
@Bean
public ItemWriter<Long> eventWriter() {
log.info("writer");
return childProfileIds -> {
Set<Long> uniqueProfileIds = new HashSet<>(childProfileIds.getItems());
uniqueProfileIds.forEach(profileId -> {
ChildProfile childProfile = childProfileService.getChildProfileWithMBTIScore(profileId);
createAndUpdateHistory(childProfile);
});
redisUtil.deleteList(BOOK_LIKE_EVENT_LIST.getKey());
};
}
private void createAndUpdateHistory(ChildProfile childProfile) {
MBTIScore currentMBTIScore = MBTIScore.fromCumulativeScore(childProfile.getCumulativeMBTIScore());
MBTI mbti = mbtiService.getMBTI(mbtiService.checkMBTIType(currentMBTIScore));
currentMBTIScore.setMbti(mbti);
ChildPersonalityHistory history = historyService.createHistory(
childProfile.getId(),
currentMBTIScore,
HistoryCreatedType.FEEDBACK
);
List<GenreScore> genreScores = childProfile.getGenreScores();
List<TopicScore> topicScores = childProfile.getTopicScores();
historyService.updatePreferredGenresByScore(history, genreScores);
historyService.updatePreferredTopicsByScore(history, topicScores);
log.info("Create History - ChildProfile ID: {}", childProfile.getId());
}
}
- Job (processLikeDislikeEventsJob)
- 단일 Step을 실행한다. (processLikeDislikeEventsStep)
- Step (processLikeDislikeEventsStep)
- Chunk 기반 처리 방식
- 한 번에 100개씩 데이터를 읽어와 처리한다.
- Reader: Redis에서 이벤트 데이터를 읽어오는 역할
- Processor: 각 이벤트 메시지를 파싱해 ChildProfile과 Book 정보를 조회하고, 해당 이벤트에 따라 점수를 변경한다.
- Writer: Chunk 내에서 고유한 ChildProfileId를 모아 각 Profile에 대해 history를 생성하고, DB에 업데이트한다. 이후 Redis에 저장된 이벤트 데이터들을 삭제한다.
성능 테스트
처리할 Redis의 데이터를 10만건으로 기준으로 해서 성능 테스트 및 개선을 진행하기로 정했다.
우선 이 코드를 처음 작성했을 때 Redis의 데이터는 몇백개 정도로 매우 적게 넣고 테스트를 진행했었고, 그 땐 문제가 없었지만 데이터가 많아졌을 때 어떻게 되는지 알아야 한다.
처음부터 10만건 이상의 데이터로 진행하기보단 어느정도의 데이터를 처리했을때 문제가 생기는지 알아보고자 5천개의 데이터부터 차근차근 늘려보기로 했다.
5000건
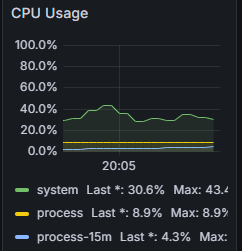

5000건의 데이터를 처리하는데 무려 40분이나 걸렸다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.c.service.ChildProfileService : get Book - bookID: 10008
Hibernate:
update
cumulativembtiscore
set
child_profile_id=?,
e_score=?,
f_score=?,
i_score=?,
j_score=?,
n_score=?,
p_score=?,
s_score=?,
t_score=?
where
id=?
Hibernate:
update
genre_score
set
child_profile_id=?,
genre_id=?,
score=?
where
id=?
Hibernate:
update
topic_score
set
child_profile_id=?,
score=?,
topic_id=?
where
id=?
Hibernate:
select
cp1_0.id,
cp1_0.birth_date,
cm1_0.id,
cm1_0.e_score,
cm1_0.f_score,
cm1_0.i_score,
cm1_0.j_score,
cm1_0.n_score,
cm1_0.p_score,
cm1_0.s_score,
cm1_0.t_score,
cp1_0.gender,
cp1_0.last_activity,
cp1_0.name,
cp1_0.profile_image,
cp1_0.user_id
from
child_profile cp1_0
join
cumulativembtiscore cm1_0
on cp1_0.id=cm1_0.child_profile_id
where
cp1_0.id=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.book.service.impl.BookServiceImpl : get Book - bookID: 674
Hibernate:
select
b1_0.id,
b1_0.age_group,
b1_0.author,
b1_0.book_image,
bt1_0.book_id,
bt1_0.id,
bt1_0.topic_id,
g1_0.id,
g1_0.image,
g1_0.name,
b1_0.page,
b1_0.price,
b1_0.publisher,
b1_0.summary,
b1_0.title
from
book b1_0
left join
genre g1_0
on g1_0.id=b1_0.genre_id
left join
book_topic bt1_0
on b1_0.id=bt1_0.book_id
where
b1_0.id=?
Hibernate:
select
gs1_0.id,
gs1_0.child_profile_id,
g1_0.id,
g1_0.image,
g1_0.name,
gs1_0.score
from
genre_score gs1_0
join
genre g1_0
on g1_0.id=gs1_0.genre_id
where
gs1_0.child_profile_id=?
and gs1_0.genre_id=?
Hibernate:
select
ts1_0.id,
ts1_0.child_profile_id,
ts1_0.score,
t1_0.id,
t1_0.image,
t1_0.name
from
topic_score ts1_0
join
topic t1_0
on t1_0.id=ts1_0.topic_id
where
ts1_0.child_profile_id=?
and ts1_0.topic_id=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.c.service.PersonalityScoreService : Update Genre and Topic scores - ChildProfile ID: 10008
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.c.service.PersonalityScoreService : Update CumulativeMBTIScore ChildProfile ID: 10008
Hibernate:
select
cm1_0.id,
cm1_0.child_profile_id,
cm1_0.e_score,
cm1_0.f_score,
cm1_0.i_score,
cm1_0.j_score,
cm1_0.n_score,
cm1_0.p_score,
cm1_0.s_score,
cm1_0.t_score
from
cumulativembtiscore cm1_0
where
cm1_0.child_profile_id=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.c.service.ChildProfileService : get Book - bookID: 10008
Hibernate:
update
cumulativembtiscore
set
child_profile_id=?,
e_score=?,
f_score=?,
i_score=?,
j_score=?,
n_score=?,
p_score=?,
s_score=?,
t_score=?
where
id=?
Hibernate:
update
genre_score
set
child_profile_id=?,
genre_id=?,
score=?
where
id=?
Hibernate:
update
topic_score
set
child_profile_id=?,
score=?,
topic_id=?
where
id=?
Hibernate:
select
cp1_0.id,
cp1_0.birth_date,
cm1_0.id,
cm1_0.e_score,
cm1_0.f_score,
cm1_0.i_score,
cm1_0.j_score,
cm1_0.n_score,
cm1_0.p_score,
cm1_0.s_score,
cm1_0.t_score,
cp1_0.gender,
cp1_0.last_activity,
cp1_0.name,
cp1_0.profile_image,
cp1_0.user_id
from
child_profile cp1_0
join
cumulativembtiscore cm1_0
on cp1_0.id=cm1_0.child_profile_id
where
cp1_0.id=?
Hibernate:
select
m1_0.id,
m1_0.description,
m1_0.mbti,
m1_0.mbti_image,
m1_0.title
from
mbti m1_0
where
m1_0.mbti=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.h.s.ChildPersonalityHistoryService : Create history ChildProfile ID: 10008
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.h.s.ChildPersonalityHistoryService : set preferred genres
Hibernate:
select
gs1_0.child_profile_id,
gs1_0.id,
gs1_0.genre_id,
gs1_0.score
from
genre_score gs1_0
where
gs1_0.child_profile_id=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.d.h.s.ChildPersonalityHistoryService : set preferred topics
Hibernate:
select
ts1_0.child_profile_id,
ts1_0.id,
ts1_0.score,
ts1_0.topic_id
from
topic_score ts1_0
where
ts1_0.child_profile_id=?
INFO 35920 --- [kkumteul] [nio-8080-exec-4] c.k.c.job.ChangePersonalityBatchConfig : Create History - ChildProfile ID: 10008
INFO 35920 --- [kkumteul] [nio-8080-exec-4] com.kkumteul.util.redis.RedisUtil : Delete Redis list: BookLikeEventList
Hibernate:
insert
into
mbtiscore
(e_score, f_score, i_score, j_score, mbti_id, n_score, p_score, s_score, t_score)
values
(?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate:
insert
into
child_personality_history
(child_profile_id, created_at, deleted_at, history_created_type, is_deleted, mbti_score_id)
values
(?, ?, ?, ?, ?, ?)
Hibernate:
insert
into
favorite_genre
(genre_id, history_id)
values
(?, ?)
Hibernate:
insert
into
favorite_genre
(genre_id, history_id)
values
(?, ?)
Hibernate:
insert
into
favorite_genre
(genre_id, history_id)
values
(?, ?)
Hibernate:
insert
into
favorite_topic
(history_id, topic_id)
values
(?, ?)
Hibernate:
insert
into
favorite_topic
(history_id, topic_id)
values
(?, ?)
Hibernate:
insert
into
favorite_topic
(history_id, topic_id)
values
(?, ?)
Hibernate:
insert
into
favorite_topic
(history_id, topic_id)
values
(?, ?)
Hibernate:
insert
into
favorite_topic
(history_id, topic_id)
values
(?, ?)
INFO 35920 --- [kkumteul] [nio-8080-exec-4] o.s.batch.core.step.AbstractStep : Step: [processLikeDislikeEventsStep] executed in 40m42s312ms
INFO 35920 --- [kkumteul] [nio-8080-exec-4] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=processLikeDislikeEventsJob]] completed with the following parameters: [{'time':'{value=1739012497892, type=class java.lang.Long, identifying=true}'}] and the following status: [COMPLETED] in 40m42s336ms
- 쿼리를 보면 각 이벤트별로 개별 수 건의 select, update 쿼리가 발생된다.
- 수 많은 DB 왕복과 처리를 해야한다.
- 동일 ChildProfile이나 Book이 여러 이벤트에 걸쳐 반복되어 조회될 수 있다. 동일 데이터임에도 매번 새롭게 조회한다.
- GenreScore가 10개, TopicScore가 25개가 존재하는데 이를 각각 Update하기 때문에 5000건을 처리하는데 수십만개의 쿼리가 발생할 수 있다.
- 한 Chunk 내에서 동일 ChildProfile이나 Book에 대한 반복 작업이 발생한다.
- 즉 중복된 엔티티를 계속 반복해서 조회하며 비효율적인 작업이 발생한다.
- update가 개별 쿼리로 실행되고 있다.
- batch 처리가 제대로 되고 있지 않다. bulk 연산에 제약이 있다.
- DB 내부에서 부하가 누적되어 전체 처리 시간이 길어진다.
개선 1. 캐싱
동일 ChildProfile이나 Book에 대한 조회가 현재 개별적으로 이루어졌다.
이미 조회한 ChildProfile이나 Book에 대한 것은 캐시를 이용해 새롭게 조회하지 않고 재사용하는 방법으로 개선할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
ChildProfile childProfile = childProfileCache.get(childProfileId);
if (childProfile == null) {
childProfile = childProfileService.getChildProfileWithMBTIScore(childProfileId);
childProfileCache.put(childProfileId, childProfile);
}
Book book = bookCache.get(bookId);
if (book == null) {
book = bookService.getBook(bookId);
bookCache.put(bookId, book);
}
- ConcurrentHashMap을 사용해 추후 병렬처리 시 문제가 없도록 하였다.
- 위 캐시를 적용하는 코드를 Processor를 새롭게 구현해 적용해도 좋고, 기존 Processor 메서드에 해당 캐시 부분을 추가해도 좋다.
- 각 이벤트 메시지를 파싱해 조회하는 부분까진 동일하지만 캐시가 적용된다.
성능 테스트

캐싱만을 적용했을 때 5000건 기준 정확히 딱 2배의 성능 향상을 보였다.
기존 40분가량 걸렸던 처리 시간이 20분으로 줄어들었다.
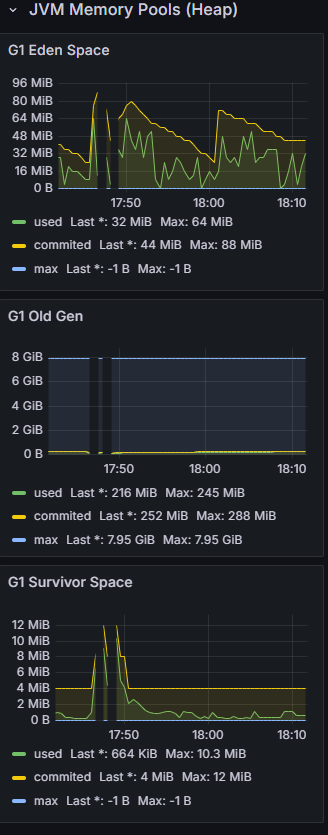
GC 작업에서도 큰 문제는 발견되지 않았다.
메모리 사용량이 주기적으로 상승했다가 급격히 상승하는 패턴이 반복되는데 이는 정상적인 GC 패턴이다. 메모리 락은 일어나지 않는다.
개선 2. 그룹화 및 Bulk 연산 처리
동일 ChildProfile에 대해 여러 좋아요/싫어요 이벤트들이 있다. 이 이벤트들을 미리 그룹화하고 누적 점수 변화를 계산한 후 그 결과를 바탕으로 한 번에 업데이트 할 수 있다.
현재 GenreScore나 TopicScore의 업데이트는 개별 UPDATE로 이루어진다. 이를 벌크 연산으로 처리해 한 번에 처리할 수 있도록 개선할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Override
public void write(Chunk<? extends ScoreUpdateEventDto> chunk) throws Exception {
Map<Long, ScoreUpdateEventDto> aggregatedMap = new HashMap<>();
for (ScoreUpdateEventDto event : chunk) {
ScoreUpdateEventDto agg = aggregatedMap.get(event.getChildProfileId());
if (agg == null) {
agg = new ScoreUpdateEventDto();
agg.setChildProfileId(event.getChildProfileId());
agg.setCumulativeDelta(0);
agg.setGenreDeltas(new HashMap<>());
agg.setTopicDeltas(new HashMap<>());
aggregatedMap.put(event.getChildProfileId(), agg);
}
agg.setCumulativeDelta(agg.getCumulativeDelta() + event.getCumulativeDelta());
final Map<Long, Double> currentGenreDeltas = agg.getGenreDeltas();
event.getGenreDeltas().forEach((genreId, delta) ->
currentGenreDeltas.merge(genreId, delta, Double::sum)
);
final Map<Long, Double> currentTopicDeltas = agg.getTopicDeltas();
event.getTopicDeltas().forEach((topicId, delta) ->
currentTopicDeltas.merge(topicId, delta, Double::sum)
);
}
aggregatedMap.forEach((childProfileId, aggregatedEvent) -> {
personalityScoreService.bulkUpdateScores(childProfileId, aggregatedEvent);
ChildProfile childProfile = childProfileService.getChildProfileWithMBTIScore(childProfileId);
createAndUpdateHistory(childProfile);
});
}
1
2
3
4
5
6
@Modifying
@Query("UPDATE GenreScore gs SET gs.score = gs.score + :delta " +
"WHERE gs.childProfile.id = :childProfileId AND gs.genre.id = :genreId")
int bulkUpdateScore(@Param("childProfileId") Long childProfileId,
@Param("genreId") Long genreId,
@Param("delta") Double delta);
- 각 ChildProfileId를 그룹화하여 동일한 ChildProfileId의 장르, 주제어 점수 변화를 저장해두었다가 계산을 적용한다.
- 그룹화된 결과를 기반으로 Bulk Update가 실행된다.
- 각 Repository에 Bulk 연산을 위한 쿼리를 적용한다.
성능 테스트

1198521ms -> 930614ms로 약 22.4%의 개선이 이루어졌다. 약 15분이 걸렸다.
벌크 연산의 결과로 보여진다.
개선 3. 트랜잭션 및 Chunk 크기 조정
현재 Chunk 내 여러 번 ChildProfile에 대한 업데이트가 일어나면서 트랜잭션이 무거워진다. 우선 이벤트를 그룹화했으므로 ChildProfile별로 트랜잭션 단위를 처리해 부담을 줄여볼 수 있다.
1
2
3
4
5
6
7
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void updateScoresAndHistory(Long childProfileId, ScoreUpdateEventDto aggregatedEvent) {
personalityScoreService.bulkUpdateScores(childProfileId, aggregatedEvent);
ChildProfile childProfile = childProfileService.getChildProfileWithMBTIScore(childProfileId);
createAndUpdateHistory(childProfile);
}
- propagation 옵션을 REQUIRES_NEW로 설정해 트랜잭션을 분리하도록 한다.
Writer에 REQUIRES_NEW를 추가했을 때 문제
처음에 단순히 Writer에 트랜잭션 전파 옵션을 설정해 트랜잭션 분리를 시도했었다.
1
2
ERROR 36896 --- [kkumteul] [nio-8080-exec-1] o.s.batch.core.step.AbstractStep : Encountered an error executing step processLikeDislikeEventsStep in job processLikeDislikeEventsJob
org.springframework.dao.InvalidDataAccessApiUsageException: Executing an update/delete query
하지만 작업 중 위와 같은 에러가 나타난다.
- update 쿼리를 실행할 때 활성된 트랜잭션이 없어서 발생하는 에러이다.
- 디버깅을 해보니 bulkUpdatesScores() 메서드에서 문제가 발생한다.
- 이유를 찾지 못했다.
- 트랜잭션이 정상적으로 생성되는 것 까지는 확인이 됐는데도 같은 에러가 반복됐다.
개선 방향 변경
트랜잭션이 무겁다고 판단해 트랜잭션 분리를 진행했다. 그런데 에러에 대한 원인을 찾지 못했고 우선 청크 사이즈를 조정해가며 개선해보기로 했다.
트랜잭션의 분리에 대한 부분은 후에 왜 에러가 발생하는지 확실하게 파악 후 개선해야할 것 같다.
성능 테스트
- 청크 사이즈 500

- 청크 사이즈를 500으로 늘렸을 때 처리 시간이 급격하게 줄었다. 1분정도가 걸렸다.
- 청크 사이즈가 100일 경우 5000건 기준 50번의 트랜잭션 커밋이 발생한다.
- 청크 사이즈가 500일 경우 5000건 기준 10번의 트랜잭션 커밋이 발생한다.
- 트랜잭션 커밋 횟수가 줄어들며 DB 커밋에 대한 오버헤드가 크게 줄어든 것 같다.
- Bulk 연산과 그룹화 로직을 적용했는데, 이 그룹화가 청크단위가 넓어지면서 더 효율적으로 작용한 것으로 보인다.
청크 사이즈를 늘려서 테스트 해봤다.
- 청크 사이즈 1000

- 청크 사이즈를 1000으로 늘렸을 때 오히려 성능이 나빠졌다.
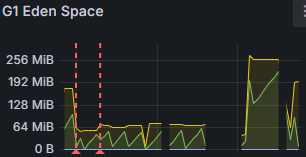
- Eden 공간의 메모리 사용량이 급격하게 튄다.
- 초반에는 거의 가득 찬 상태를 보인다.
- 데이터가 늘어나면 Full GC 가능성이 있다.
- 힙 영역 전체를 대상으로 수행하는 메모리 정리 작업이다.
- 모든 공간을 검사하고 불필요한 객체를 제거한다.
- 이는 공간이 부족할 때 나타나게 된다.
- Full GC가 시작되면 애플리케이션의 모든 스레드가 멈추게 되어 피해야 한다.
- 즉, 청크 크기가 메모리 사용량을 늘렸고 GC 부하를 증가시켰음을 알 수 있다.
청크 사이즈 750으로도 테스트해본 결과 청크 사이즈 500과 큰 차이는 없었다.
데이터 5000개 기준 충분한 성능 개선이 이루어졌다고 판단해 이제 데이터를 10만개로 늘린 후 테스트를 해보기로 결정했다.
성능 테스트 (데이터 10만개)

5000개 기준 1분, 10만개 기준 20분이 걸렸다.
데이터 개수의 차이만큼 더 걸린 셈이다.
개선 4. 병렬 처리
대량의 데이터이기 때문에 병렬 처리는 매우 효율적일 것이라고 생각되었다.
Spring Batch 파티셔닝을 이용해 처리 작업을 여러 스레드에서 동시에 처리할 수 있도록 해보았다.
병렬처리에도 발생하는 트랜잭션 문제
병렬 처리 코드를 적용하니, 개선 3에서 발생했던 트랜잭션 문제가 그대로 발생했다.