
유레카를 진행하면서 프로젝트 중 내가 담당하지 않았던 부분들을 해보고자 했다. 여러 기능들을 맡아서 했었지만 데이터 조회 등에서 쿼리 실행 계획을 분석해서 성능 개선을 해본다던가, 배치 작업에 대해 구현은 했지만 배치 작업 또한 데이터가 많아졌을 때 성능에 문제가 있을 수 있어 그 부분을 개선해본다던가 하는 것을 안해봐서 따로 진행해보고자 했다.
우선 프로젝트 진행 당시 내가 맡지 않았던 부분이지만, 따로 개인 프로젝트를 만들어 진행하는 것 보다 기존 코드를 이용하는 것이 좋을 것 같아 사용해보려고 한다.
기존 데이터 조회 쿼리
도서 목록을 조회하는 부분이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Query(value = """
SELECT DISTINCT b FROM Book b
JOIN FETCH b.genre bg
JOIN FETCH b.bookTopics bt
JOIN FETCH bt.topic t
WHERE LOWER(b.title) LIKE LOWER(CONCAT('%', :keyword, '%'))
OR LOWER(b.author) LIKE LOWER(CONCAT('%', :keyword, '%'))
OR LOWER(t.name) LIKE LOWER(CONCAT('%', :keyword, '%'))
OR LOWER(bg.name) LIKE LOWER(CONCAT('%', :keyword, '%'))
ORDER BY CASE
WHEN b.title LIKE CONCAT('%', :keyword, '%') THEN 0
WHEN b.author LIKE CONCAT('%', :keyword, '%') THEN 1
WHEN t.name LIKE CONCAT('%', :keyword, '%') THEN 2
WHEN bg.name LIKE CONCAT('%', :keyword, '%') THEN 3
ELSE 4 END, b.id ASC
""")
Page<Book> findBookListByKeyword(
@Param("keyword") final String keyword,
final Pageable pageable);
검색어를 입력하면 제목, 주제어, 작가, 장르로 책들이 검색이 된다. 검색어는 하나이기 때문에 하나의 검색어를 가지고 여러 필드에서 대소문자 구분 없이 여러 필드를 조회한다.
처음 이 코드를 작성하고 멘토분들께 피드백을 받았을 때 이 부분에 대해 질문하지 않았는데 코드를 보시고 직접 피드백을 해주셨었다.
LIKE CONCAT 관련해서 index를 이용하지 못한다. 풀스캔이 발생한다. 한 번 해당 내용에 대해 검색해보고 왜 풀스캔이 발생하는지 체크해보면 좋을 것 같다. 그리고 대안을 찾아보자. 보통 다른 방식을 채택한다.
쿼리 실행 계획
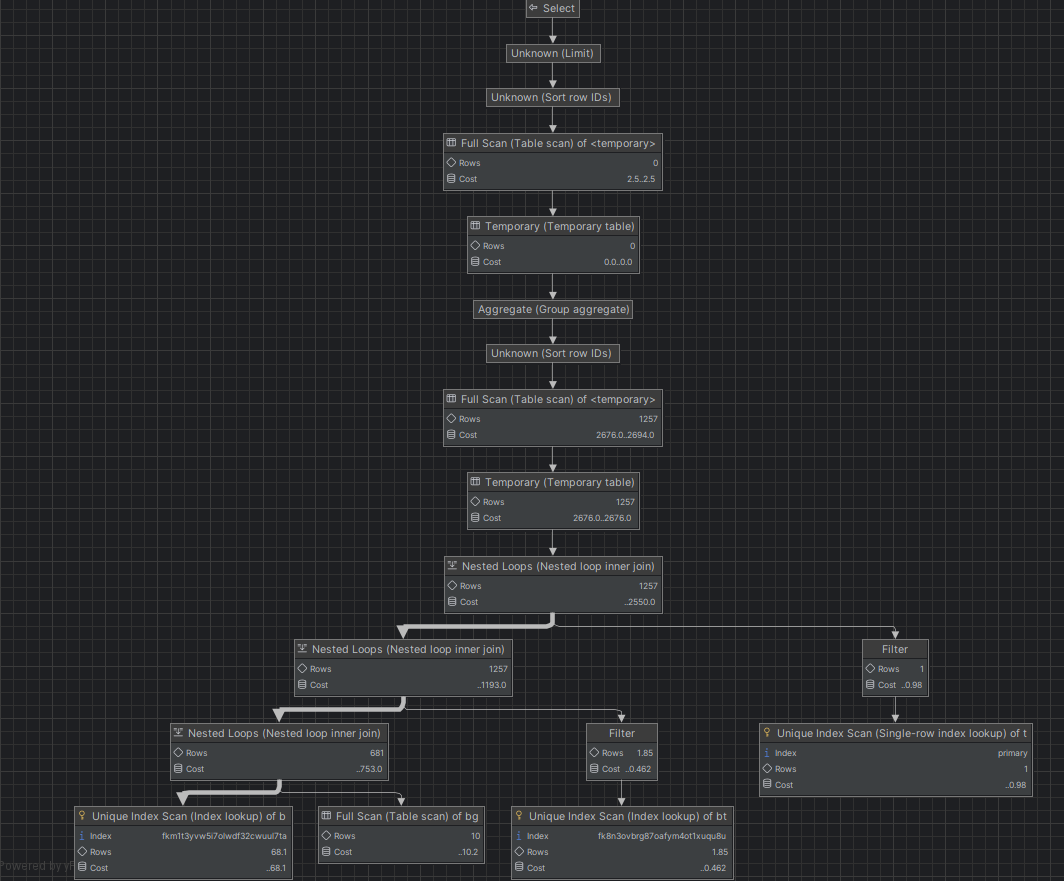
- Full Scan
- 테이블 전체를 탐색해 데이터를 찾는다.
- 따라서 데이터가 많아질 수록 시간이 오래걸려 성능 저하에 문제가 생긴다.
- 인덱스를 추가하거나 쿼리를 최적화하여 해결할 수 있다.
- Temporary (임시 테이블)
- 쿼리 실행 중 데이터를 임시로 저장하는 테이블이다. 메모리 또는 디스크 기반 테이블이다.
- Group By, Order By, Distinct 사용 시 자주 발생된다.
- 메모리 사용량이나 디스크 I/O 증가로 성능이 저하될 수 있다.
- 인덱스를 최적화하거나 불필요한 Order By절을 제거하면 해결할 수 있다.
- 쿼리 실행 중 데이터를 임시로 저장하는 테이블이다. 메모리 또는 디스크 기반 테이블이다.
- Nested Loops (중첩 루프 조인)
- 두 개 이상의 테이블을 조인할 때, 한 개의 테이블을 기준으로 다른 테이블을 반복 조회한다.
- 데이터가 많아지면 조인 연산 비용이 급격하게 증가한다.
- Index Join을 활용해 조인 성능을 최적화해볼 수 있다.
- Rows (처리되는 행의 개수)
- 해당 단계에서 처리되는 행의 개수이다.
- Rows 값이 높으면 실행 시간이 길어진다.
- 인덱스를 활용해 스캔해야 하는 Row 개수를 줄여볼 수 있다.
- Cost (쿼리 실행 비용)
- SQL 엔진이 해당 연산을 수행하는 데 필요한 상대적인 비용이다.
- Cost 값이 높을 수록 쿼리 실행 시간이 오래 걸릴 수 있다.
- 2670.0 .. 2694.0
- 처음 숫자는 첫 번째 결과를 반환하기까지 걸리는 비용
- 두 번째 숫자는 쿼리가 완전히 실행될 때까지 총 비용
- Cost 차이가 크면 해당 연산이 많은 데이터를 처리하고 있을 가능성이 높다.
- Cost 값은 일반적으로 몇 천 단위 이상이라면 성능에 부담을 줄 가능성이 크다고 해석된다.
- Unique Index Scan
- 유일한 값을 빠르게 찾는다.
- Primary Key 또는 UNIQUE가 존재하는 컬럼에서 검색할 때 사용된다.
- where id = 1과 같이 equal 또는 in 연산자로 유일한 값을 검색할 때 사용된다.
- 쿼리 실행 계획에서 이 부분이 나타난다면 성능면에서는 좋은 신호이다.
참고
현재 위 이미지는 explain analyze를 사용하고 있다.
explain으로 테스트하는 방법과 explain analyze로 테스트하는 방법이 있는데 explain은 예상 실행 계획을 보여주는 것이고, explain analyze는 쿼리를 실제로 실행한 후 실행 경로와 비용을 보여주는 것이다.
실제 성능을 테스트해야 하므로 explain analyze를 사용했다.
- explain 결과 정보
- table: 쿼리에서 참조하는 테이블 목록
- type: 테이블을 검색하는 방식
- possible_keys: 사용 가능한 인덱스 목록
- key: 실제로 사용된 인덱스
- rows: 이 단계에서 조회할 것으로 예상되는 행의 개수
- filtered: 필터링 후 남는 데이터의 비율 (100이면 모든 행이 남는 것)
- Extra: 추가적인 연산
LIKE CONCAT 사용 시 풀스캔 발생 이유
피드백처럼 쿼리 실행 계획을 분석해보면 실제로 풀스캔이 발생한다.
1
WHERE LOWER(b.title) LIKE LOWER(CONCAT('%', :keyword, '%'))
- 이러한 형태의 와일드카드 검색은 B-Tree 인덱스를 활용하지 못한다.
- 인덱스는 문자열을 정렬된 순서로 저장하는데, 앞에 %가 있을 경우 정렬 구조를 활용할 수 없기 때문이다.
- 보통 B-Tree 기반의 인덱스는 왼쪽부터 차례대로 검색한다.
- 하지만 현재 구조에는 문자열의 중간이나 끝 부분에도 해당 키워드가 포함될 수 있다.
- Where 조건을 만족하는 행이 어디있는지 인덱스만으로 판단할 수 없는 구조인 것이다.
- 따라서 DB는 모든 행을 조회하며 하나하나 문자열을 비교해야 하기 때문에 풀스캔이 발생하는 것.
- 또한 LOWER() 함수도 인덱스 사용을 방해할 수 있다.
- 인덱스는 일반적으로 원본 값을 저장하는데, Lower()를 적용할 경우 원본 문자열이 아닌 소문자로 변환된 값을 검색해야 하기 때문에 기존 인덱스를 활용하지 못할 수 있다.
개선 방향
우선 책 데이터가 현재 800개인 상황에서 테스트를 했었다. 기존에 크롤링을 진행했던 데이터가 800개 정도이기 때문이다.
따라서 책 데이터를 임의로 100만개 정도로 삽입한 후 테스트를 진행해 개선을 진행해보려고 한다.
- 데이터 삽입
- Jmeter로 응답 시간 측정 (동시 요청 수를 증가시킨다.)
- 쿼리 실행 계획 분석
- 쿼리 개선 후 재 분석
데이터 삽입
100만개의 책 데이터를 삽입하고 테스트해보려고 한다.
MySQL Stored Procedure를 활용해 100만개의 데이터를 삽입해보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
DELIMITER $$
CREATE PROCEDURE InsertBooks(IN num_books INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= num_books DO
INSERT INTO book (title, author, publisher, price, page, age_group, summary, book_image, genre_id)
VALUES (
CONCAT('책 제목 ', i),
CONCAT('저자 ', i),
CONCAT('출판사 ', i),
CONCAT(FLOOR(RAND() * 50000) + 5000, '원'),
CONCAT(FLOOR(RAND() * 1000) + 100, '쪽'),
CASE FLOOR(RAND() * 5)
WHEN 0 THEN '전체 이용가'
WHEN 1 THEN '10세 이상'
WHEN 2 THEN '13세 이상'
WHEN 3 THEN '16세 이상'
ELSE '19세 이상'
END,
CONCAT('이 책은 ', i, '번 책입니다.'),
NULL,
FLOOR(1 + (RAND() * 9)) -- genre_id (1~10 랜덤)
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
1
CALL InsertBooks(1000000);
데이터의 내용 자체는 중요하지 않기 때문에 i 값을 증가시키거나 랜덤한 수를 넣어 삽입했다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
DELIMITER $$
CREATE PROCEDURE InsertBookTopics(IN num_books INT)
BEGIN
DECLARE book_counter INT DEFAULT 801;
DECLARE max_books INT DEFAULT num_books;
WHILE book_counter <= max_books DO
INSERT INTO book_topic (book_id, topic_id)
VALUES (
book_counter,
FLOOR(RAND() * 25) + 1
);
INSERT INTO book_topic (book_id, topic_id)
VALUES (
book_counter,
FLOOR(RAND() * 25) + 1
);
SET book_counter = book_counter + 1;
END WHILE;
END$$
DELIMITER ;
CALL InsertBookTopics(1000000);
마찬가지로 주제어 또한 각 책에 2개씩 매핑하여 삽입해주었다. 총 200만개의 행이 추가된다.
기존에 800개의 책 데이터가 있었기 때문에 book_counter를 801로 세팅해주고 시작했다.
모두 삽입하는데 30분 정도가 소요됐다.
테스트 결과
이제 쿼리 실행 계획과 Jmeter 테스트를 진행해보려 한다.
쿼리 실행 계획 분석
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
SELECT
b.id AS bookId,
b.title AS bookTitle,
b.book_image AS bookImage,
GROUP_CONCAT(DISTINCT t.name ORDER BY t.name SEPARATOR ', ') AS topicNames
FROM book b
INNER JOIN genre bg ON b.genre_id = bg.id
INNER JOIN book_topic bt ON b.id = bt.book_id
INNER JOIN topic t ON bt.topic_id = t.id
WHERE LOWER(b.title) LIKE LOWER(CONCAT('%', '이' , '%'))
OR LOWER(b.author) LIKE LOWER(CONCAT('%', '이' , '%'))
OR LOWER(bg.name) LIKE LOWER(CONCAT('%', '이' , '%'))
OR LOWER(t.name) LIKE LOWER(CONCAT('%', '이' , '%'))
GROUP BY
b.id,
b.title,
b.book_image
ORDER BY
CASE
WHEN b.title LIKE CONCAT('%', '이' , '%') THEN 0
WHEN b.author LIKE CONCAT('%', '이' , '%') THEN 1
WHEN MIN(t.name) LIKE CONCAT('%', '이' , '%') THEN 2
WHEN bg.name LIKE CONCAT('%', '이' , '%') THEN 3
ELSE 4
END,
b.id ASC
LIMIT 10 OFFSET 0
데이터를 삽입 후 똑같이 같은 SQL 쿼리로 explain analyze를 실행한 결과 Out of Memory가 발생했다.
1
Out of sort memory, consider increasing server sort buffer size
위에서 데이터가 800개일 때의 결과를 봤었는데, 풀스캔이 발생했었다. 그러면서 MySQL이 감당할 수 있는 메모리 한계를 초과하게 된 것이다.
따라서 쿼리를 직접 실행하지 않는 EXPLAIN만 실행해서 계획을 확인하고, 개선을 한 후 결과를 봐야할 것 같다.
EXPLAIN 결과

- book_genre 테이블에서 모든 행을 검색하여
- type = all -> 풀스캔 발생
- key = null -> 사용할 수 있는 인덱스가 없음.
- rows = 10 -> book_genre 테이블의 총 행 개수
- Extra = Using temporary, Using filesort -> Order By, Group By 과정에서 임시 테이블을 사용 중.
- 따라서 적절한 인덱스가 없어 장르 조회 시 풀스캔이 발생하고 있고, 이를 개선해야 한다.
- book 테이블에서 99517개의 행을 검색한다. (예상 수치)
- LIKE % % 조건에서 인덱스를 활용할 수 없어 풀스캔 발생.
이 때 id 값이 모두 1인데 따라서 위부터 아래의 순서로 실행된다는 것이 아닌, MySQL 옵티마이저가 최적의 실행 순서를 결정해서 보여준 결과이다.
실제 실행 순서를 보려면 EXPLAIN ANALYZE를 확인해야 한다. 따라서 EXPLAIN ANALYZE를 확인하기 위해 개선을 먼저 해보자.
현재 데이터를 추가한 상태로 api를 직접 한 번 호출해 응답 시간을 살펴보면 아래와 같다.

거의 14분이 걸렸다. 기존 데이터가 800개일 때 같은 쿼리를 사용해도 응답시간에 크게 문제가 없었지만 데이터가 증가하면 사실상 사용하지 못하는 수준의 쿼리인 것이다.
기존 개선 방법
팀원분이 담당했었고 피드백 이후 개선을 하셨었다.
1
2
3
4
5
create index idx_books_title_author on book(title, author);
create index idx_books_genre_id on book(genre_id);
create index idx_topics_name on topic(name);
create index idx_book_topics_book_id_topic_id on book_topic(book_id, topic_id);
create index idx_genres_name on genre(name);
이렇게 인덱스를 설정해주고,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Query(value = """
SELECT b FROM Book b
JOIN b.genre bg
JOIN b.bookTopics bt
JOIN bt.topic t
WHERE b.title LIKE CONCAT('%', :keyword, '%')
OR b.author LIKE CONCAT('%', :keyword, '%')
OR t.name LIKE CONCAT('%', :keyword, '%')
OR bg.name LIKE CONCAT('%', :keyword, '%')
ORDER BY CASE
WHEN b.title LIKE CONCAT('%', :keyword, '%') THEN 0
WHEN b.author LIKE CONCAT('%', :keyword, '%') THEN 1
WHEN t.name LIKE CONCAT('%', :keyword, '%') THEN 2
WHEN bg.name LIKE CONCAT('%', :keyword, '%') THEN 3
ELSE 4 END, b.id ASC
""")
Page<Book> findBookListByKeyword(
@Param("keyword") final String keyword,
final Pageable pageable);
- DISTINCT 제거
- LOWER 제거
- 인덱스 사용
- Book, Genre가 조인하는 경우 genre_id에 대해 인덱스 스캔을 활용해 조인 비용이 줄어든다.
- BookTopic과 Topic이 조인할 때 최적화할 수 있다.
이렇게 개선을 하셨었다.
개선 결과

응답시간이 13분에서 1분으로 매우 많이 줄었다.

Explain으로 확인해봐도 type이 index로 바뀐 것을 확인할 수 있다.
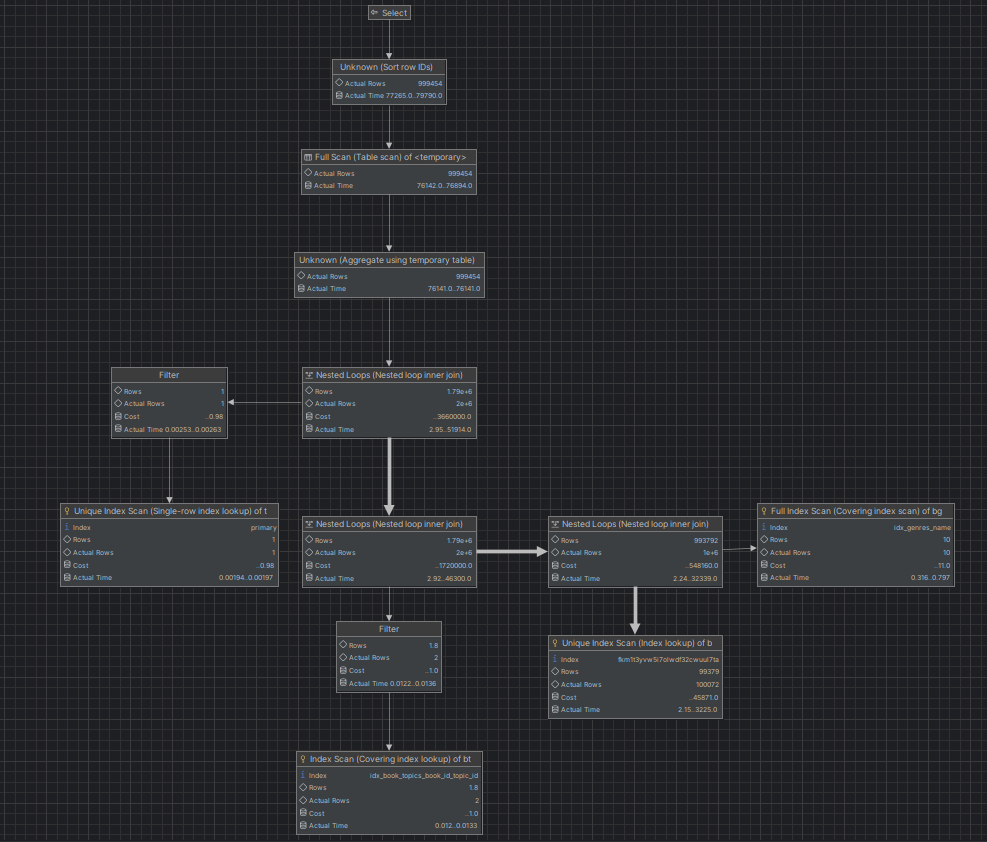
쿼리 실행 계획도 풀스캔이 줄어든 모습을 확인할 수 있다.
- LIKE 조건을 유지했으나 인덱스를 활용해 JOIN속도와 검색 속도를 향상시켰다.
- 기존 book 테이블에 접근 시 FullScan이 일어났었는데, Index Scan이 발생한다.
- Covering index lookup: 필요한 데이터를 인덱스에서 바로 조회해 테이블 접근을 줄인다.
- topic이나 genre 테이블에서도 인덱스를 활용한 스캔이 이루어졌다.
- 전체 데이터를 읽는 대신, 필요한 데이터만을 검색할 수 있다.
- 쿼리실행비용 또한 줄어들었다.
- Filesort가 제거되었다.
- MySQL이 정렬을 위해 별도의 임시 테이블을 생성하여 처리하는 것.
그럼에도 여전히 100만건 이상의 데이터에서는 활용할 수 없는 정도이다.
여전히 중첩 루프 조인이 발생하고 Like 조건을 사용해 인덱스 범위 검색을 활용할 수 없다.
인덱스 관련 리마인드
- 자주 검색되는 컬럼에 인덱스를 추가하면 조건 검색이나 JOIN, 정렬 성능을 향상시킨다.
- filesort가 필요없다.
- join시 모든 행을 비교할 필요가 없다. 특정 키 값으로 매칭이 가능하다.
- 검색 또한 인덱스를 통해 범위 검색이나 필요 데이터를 빠르게 찾을 수 있다. 풀스캔을 하지 않는다.
- 그러나 인덱스를 마구잡이로 추가하면 insert, update, delete 성능이 떨어진다.
- 더해 인덱스 또한 데이터이기 때문에 저장 공간을 차지한다.
- 인덱스의 갱신이 필요하기 때문.
- 따라서 읽기가 많은 테이블이라면 인덱스를 적극 활용해도 좋지만, 쓰기가 많은 테이블은 최소한으로 설정해야 한다.
개선 1 (LIKE 구문 제거 및 FULLTEXT INDEX 활용)
우선 EXPLAIN ANALYZE를 사용하기 위해 Out of Memory 에러의 발생을 막아야 한다.
그래야 실제 쿼리 실행 계획을 분석하고 개선해볼 수 있다.
LIKE % % 구문을 제거하고 FULLTEXT INDEX를 적용
1
2
3
4
5
6
7
ALTER TABLE book ADD FULLTEXT(title, author);
ALTER TABLE genre ADD FULLTEXT(name);
ALTER TABLE topic ADD FULLTEXT(name);
ANALYZE TABLE book;
ANALYZE TABLE genre;
ANALYZE TABLE topic;
- 위 SQL 문들을 통해 title, author 그리고 genre의 이름과 topic의 이름에 fulltext index를 적용한다.
그리고 조회 쿼리를 수정해준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
SELECT
b.id AS bookId,
b.title AS bookTitle,
b.book_image AS bookImage,
GROUP_CONCAT(DISTINCT t.name ORDER BY t.name SEPARATOR ', ') AS topicNames
FROM book b
INNER JOIN genre bg ON b.genre_id = bg.id
INNER JOIN book_topic bt ON b.id = bt.book_id
INNER JOIN topic t ON bt.topic_id = t.id
WHERE MATCH(b.title, b.author) AGAINST ('책' IN NATURAL LANGUAGE MODE)
OR MATCH(bg.name) AGAINST ('책' IN NATURAL LANGUAGE MODE)
OR MATCH(t.name) AGAINST ('책' IN NATURAL LANGUAGE MODE)
GROUP BY
b.id,
b.title,
b.book_image
ORDER BY FIELD(
MATCH(b.title, b.author) AGAINST ('책' IN NATURAL LANGUAGE MODE),
MATCH(bg.name) AGAINST ('책' IN NATURAL LANGUAGE MODE),
MIN(MATCH(t.name) AGAINST ('책' IN NATURAL LANGUAGE MODE))
) ASC, b.id ASC
LIMIT 10 OFFSET 0;
- FULLTEXT INDEX를 추가하고 MATCH를 사용한다.
- 단어 또는 구문에 대해 검색한다.
- 해당하는 검색어가 포함된 데이터를 조회한다.
- 모드는 3가지가 존재한다.
- Natural Language: 검색 문자열을 단어 단위로 분리하고, 단어 중 하나라도 포함되는 행을 찾는다.
- Boolean: 검색 문자열을 단어 단위로 분리 후 추가적으로 검색 규칙을 적용한 단어가 포함되는 행을 찾는다.

여전히 풀 스캔이 되고 있고, 실행 시간도 매우 긺. 물론 Out Of Memory 에러가 발생하지는 않아 explain analyze는 실행이 가능하지만, 근본적인 해결이 되진 않았음.
FULLTEXT INDEX를 활용하고 있는지 체크해야 한다.
1
2
3
4
EXPLAIN FORMAT=JSON
SELECT b.id, b.title
FROM book b
WHERE MATCH(b.title, b.author) AGAINST ('책' IN NATURAL LANGUAGE MODE);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "1.10"
},
"table": {
"table_name": "b",
"access_type": "fulltext",
"possible_keys": ["title"],
"key": "title",
"used_key_parts": ["title"],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 1,
"filtered": "100.00",
"ft_hints": "sorted",
"cost_info": {
"read_cost": "1.00",
"eval_cost": "0.10",
"prefix_cost": "1.10",
"data_read_per_join": "6K"
},
"used_columns": ["id", "author", "title"],
"attached_condition": "(match `kkumteul`.`b`.`title`,`kkumteul`.`b`.`author` against ('책'))"
}
}
}
- 구문을 실행한 결과이다.
- 이 중 access_type을 보면 fulltext라고 되어 있는데, 이는 fulltext 인덱스를 사용하고 있다는 것을 확인할 수 있는 것이다.
- key: title -> 사용 가능한 인덱스에 title이 포함되어 있다.
- filtered: 100.00 -> 쿼리의 필터링 정확도가 높다.
이렇게 MATCH 구문과 FULLTEXT INDEX를 잘 활용하고 있는데 왜 개선이 안된걸까?
- WHERE 절에서는 MATCH가 제대로 동작하지만 JOIN, GROUP BY, ORDER BY 과정에서 비효율적으로 실행되고 있을 수 있다.
- MATCH가 적용된 이후 JOIN 시 불필요한 데이터까지 읽게 되면서 성능이 저하될 수 있다.
- GROUP_CONCAT() 구문에서 MySQL이 임시 테이블과 정렬을 수행하면서 속도가 느려질 수 있다.
여러 테스트
어디서 풀스캔이 일어나는지, 왜 결과가 제대로 나타나지 않는지 확인하고 싶어 JOIN, ORDER BY문 등을 주석처리하고 실행해보았다.
JOIN은 STRAIGHT_JOIN을 사용했고, ORDER BY문을 제거했는데도 풀스캔이 일어났다.
그리고 MATCH를 썼을 때 결과가 0개로 나오길래 다시 LIKE 구문을 써서 시도해봤더니 의도한대로 결과들이 나타났다. 물론 조회에 걸리는 시간은 40초 이상이 걸렸다.
이 40초도 단순 제거로 의도한 결과를 포기한 개선임에도 사용할 수 없는 수준이라 다른 방법이 필요하다고 판단했다.
개선 2. (Denormalization 및 단일 검색 컬럼 도입)
현재 Nested JOIN, 그리고 LIKE 검색으로 인한 풀스캔으로 쿼리 실행 시간이 길다는 것이 문제다.
search_text 컬럼을 도입해서 단일 컬럼으로 FULLTEXT 검색을 수행하는 방법을 시도해본다.
검색에 필요한 컬럼들을 모두 합친 컬럼을 하나 만드는 방법이다. 일종의 비정규화라고 볼 수 있다.
비정규화(Denormalization)를 통한 개선
- 검색에 필요한 데이터를 하나의 컬럼으로 저장해 JOIN을 줄이고 단일 테이블에서 검색 가능하도록 한다.
- 장점: 읽기 성능이 당연히 매우 좋아진다.
- 단점: 쓰기 성능이 감소한다.
search_text 컬럼 추가
1
ALTER TABLE book ADD COLUMN search_text TEXT;
1
2
3
4
5
6
7
8
9
UPDATE book b
SET b.search_text = CONCAT_WS(' ',
b.title,
b.author,
(SELECT bg.name FROM genre bg WHERE bg.id = b.genre.id),
(SELECT GROUP_CONCAT(t.name SEPARATOR ' ') FROM book_topic bt
JOIN topic t ON bt.topic_id = t.id WHERE bt.book_id = b.id)
)
WHERE b.id IS NOT NULL;
- MySQL에서 WHERE 절이 없으면 UPDATE 를 차단한다.
- Unsafe query: ‘Update’ statement without ‘where’ updates all table rows at once
- 따라서 WHERE 조건으로 모든 행을 만족하는 조건을 걸어 safe update mode를 회피할 수 있다.
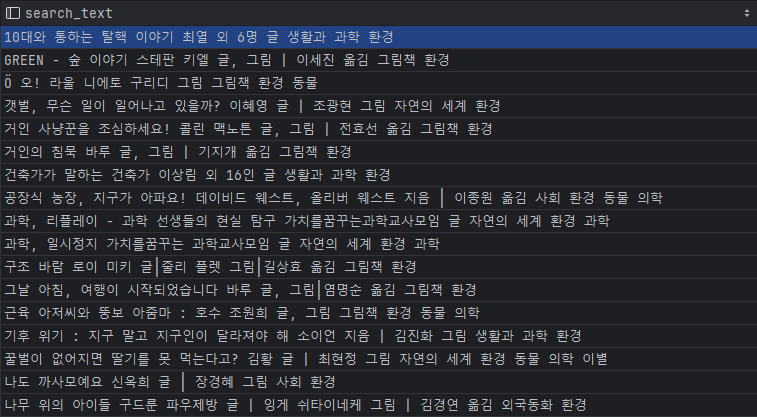
결과적으로 이렇게 검색에 필요한 텍스트들을 하나의 컬럼으로 묶을 수 있다.
1
2
ALTER TABLE book ADD FULLTEXT(search_text);
ANALYZE TABLE book;
그리고 이 컬럼을 통해 FULLTEXT INDEX를 생성하고 쿼리를 테스트해보자.
문제1. (FULLTEXT INDEX 생성 시 문제)
그런데 검색이 제대로 안된다.
FULLTEXT INDEX가 제대로 생성된 것을 확인했고, LIKE 검색으로 했을 때 정상적으로 검색되지만 MATCH AGAINST를 사용해 검색했을 땐 결과가 제대로 나오지 않는다.
- 기본적으로 FULLTEXT INDEX를 생성할 때 built-in-parser를 이용해서 생성하게 된다.
- 어절 단위로 문장들을 파싱해 우리가 원하는 LIKE를 사용하는 결과와 검색결과가 다르게 나타난다.
- 안녕하세요 라는 문장을 예시로 들면 녕하라는 단어로 찾을 수 없다.
이 문제는 내장 Parser중 ngram parser라는 것이 존재하는데 최소 Token 사이즈만큼 조각내어 파싱하게 된다.
1
select @@ngram_token_size
이 구문으로 확인해보면 기본 값이 2임을 확인할 수 있다.
1
CREATE FULLTEXT INDEX search_text_index ON book(search_text) WITH PARSER ngram;
이 후 인덱스를 다시 만들어줘야 한다.
한글자 검색을 위해 최소 Token 사이즈를 조정해주어야 하는데, 이 때 주의해야 할 점은 당연히 토큰 사이즈를 줄이면 인덱스를 더 많이 생성하기 때문에 insert, update, delete 기능은 더 떨어질 수 있어 적절한 크기를 설정하는 것이 중요하다.
문제 2. (MySQL MINIMUN WORD LENGTH)
위와 같이 처리해도 여전히 검색이 안된다.
MySQL에서는 기본적으로 FULLTEXT INDEX가 3글자 이상 단어만 색인할 수 있도록 되어 있다.
1
SHOW VARIABLES LIKE 'ft_min_word_len';
이 구문을 실행해보면 4로 되어 있었다. 이를 확인하고 검색어를 4글자로 검색해보니 검색 결과가 매우 잘 나왔다.
1
SET GLOBAL ft_min_word_len = 1;
이런식으로 변경하려면 ngram_token_size나 ft_min_word_len 모두 read only variable이라며 변경이 되지 않는다.
MySQL의 my.ini 설정 파일에서 [mysqld] 섹션 아래에 추가해주고 MySQL 서버를 재시작해주면 설정이 완료된다.
이 또한 1로 설정해 다시 인덱스를 생성해보았다.
결과적으로는 ngram_token_size, ft_min_word_len 모두 변경 후 FULLTEXT INDEX를 재생성해주어야 한다.
이제 정상적으로 LIKE를 사용했을 때와 같이 제대로 된 검색이 이루어졌다.
ORDER BY MATCH AGAINST의 역할
- MySQL은 검색된 단어와 문서의 관련성을 점수로 계산한다.
- 검색어 단어가 많이 포함된 문서가 더 높은 점수를 가지게 되고 우선적으로 정렬된다.
- 기존의 LIKE 사용 처럼 제목, 작가 이러한 특정 필드의 우선순위를 지정해준 부분과는 다르긴 하지만 검색 속도의 향상을 위해 일부는 포기해야 하는 것이다.
그래도 아쉽기 때문에 ORDER BY 구문을 조금 수정해서 LIKE 구문을 사용했을 때와 비슷한 동작을 하도록 구현해보자.
1
2
3
4
5
6
7
8
9
10
11
12
SELECT b.id AS bookId, b.title AS bookTitle, b.book_image AS bookImage,
(SELECT GROUP_CONCAT(DISTINCT t.name ORDER BY t.name SEPARATOR ', ')
FROM book_topic bt
JOIN topic t ON bt.topic_id = t.id
WHERE bt.book_id = b.id) AS topicNames,
(MATCH(b.title) AGAINST ('환경' IN BOOLEAN MODE) * 3 +
MATCH(b.author) AGAINST ('환경' IN BOOLEAN MODE) * 2 +
MATCH(b.search_text) AGAINST ('환경' IN BOOLEAN MODE)) AS relevance_score
FROM book b
WHERE MATCH(b.search_text) AGAINST ('환경' IN BOOLEAN MODE)
ORDER BY relevance_score DESC, b.id ASC
LIMIT 10 OFFSET 0;
단, 이렇게 구현하기 위해서는 title과 author에도 FULLTEXT INDEX를 생성해주어야 하고, 생성하게 되면 INDEX 생성에 대한 단점이 발생할 수 있기 때문에 트레이드 오프가 있다.
같은 쿼리를 이렇게 가중치를 둔 버전과 안 둔 버전으로 결과 값이 많은 검색어를 이용하여 실행해 보았을 때 응답 시간이 각각 16초, 15초가 걸렸다. 성능에도 조금 차이가 나타난다.
다만 Insert, update, delete 시 성능은 차이가 날 것이기 때문에 상황에 맞게 구현하면 될 것 같다.
개선 3. (조인 및 정렬 최적화)
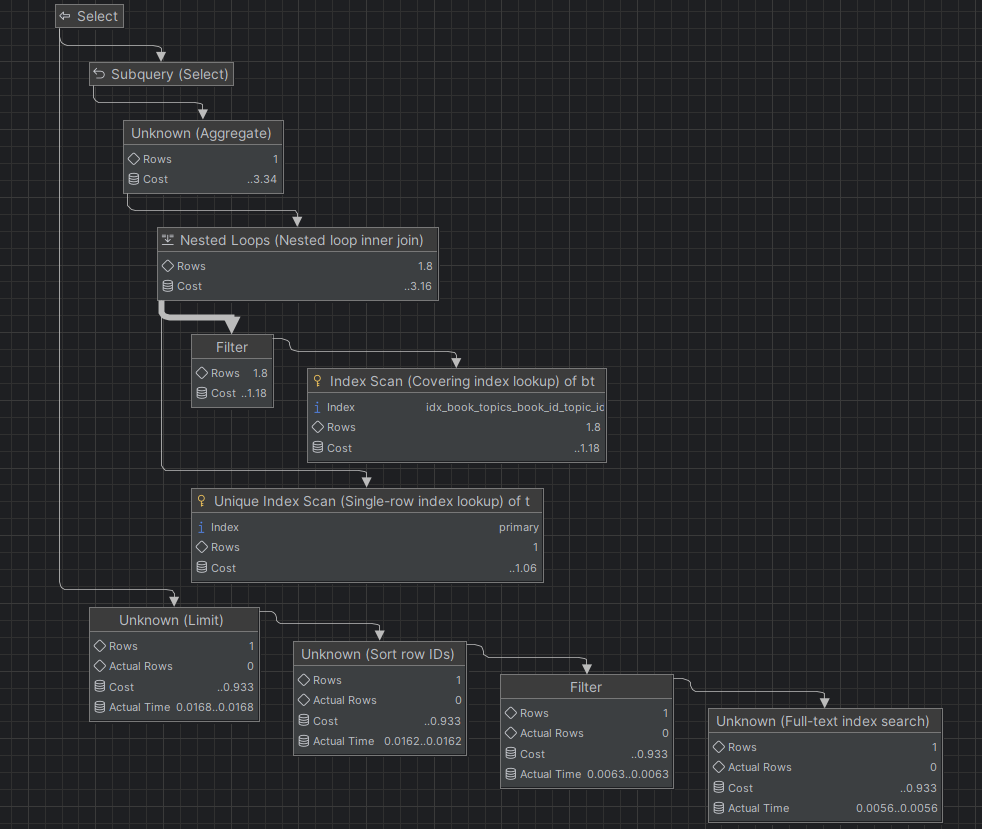
현재 개선된 쿼리 실행 계획이다.
- FullText Index로 효율적인 검색을 할 수 있었다.
- Actual Time: 0.0056으로 매우 빠르게 수행된다.
- Index Scan
- Book Topic 테이블에서
문제 1. (검색 결과가 많을 시 검색 속도가 느림)
검색 결과가 적은 경우 검색 응답 속도가 매우 빠르다.
하지만 책 데이터를 임의로 넣어 책 이라는 검색어에 데이터가 100만개가 넘는 결과가 나오는데 이럴 경우 응답 시간은 10초가 넘어가게 된다.
현재 ORDER BY를 적용하고 있는데, 이 정렬에서 결과 데이터가 많을 때 속도 저하가 발생한다.
- 현재 ORDER BY 연산이 모든 결과를 정렬 후 LIMIT을 적용하도록 되어 있다.
- 많은 데이터가 정렬 연산에 포함되어 정렬 비용이 많아질 수 있다.
- LIMIT을 먼저 적용 후 정렬을 수행한다.
- 기존에는 결과가 100만개라면 100만개의 검색 결과를 모두 정렬한 후 상위 10개만 추출하는 비효율적인 방식이었다.
- 물론 LIMIT을 먼저 적용하기 때문에 검색 결과의 정확한 우선순위는 지켜지지 않을 수 있다.
- 기존에 Nested Loops가 발생
- book 테이블에서 검색어가 포함된 책들을 필터링한다.
- 이후 각 책마다 book_topic을 조회하고, 각 book_topic마다 topic을 조회하기 때문에 발생한다.
- 즉, 조인 테이블이 많아 GROUP_CONCAT이 불필요한 연산을 발생시켰다.
1
2
3
4
5
6
7
8
9
10
11
12
SELECT * FROM (
SELECT b.id, b.title, b.book_image, b.search_text AS topicNames,
(MATCH(b.title) AGAINST ('책' IN BOOLEAN MODE) * 3 +
MATCH(b.author) AGAINST ('책' IN BOOLEAN MODE) * 2 +
MATCH(b.search_text) AGAINST ('책' IN BOOLEAN MODE)) AS relevance_score
FROM book b
WHERE MATCH(b.search_text) AGAINST ('책' IN BOOLEAN MODE)
ORDER BY MATCH(b.search_text) AGAINST ('책' IN BOOLEAN MODE) DESC
LIMIT 1000
) AS subquery
ORDER BY relevance_score DESC
LIMIT 10 OFFSET 0;
이렇게 개선했다.
- JOIN 없이 서브쿼리를 활용해 Nested Loops를 제거한다.
- LIMIT 1000을 미리 적용해 정렬 부담을 줄인다.
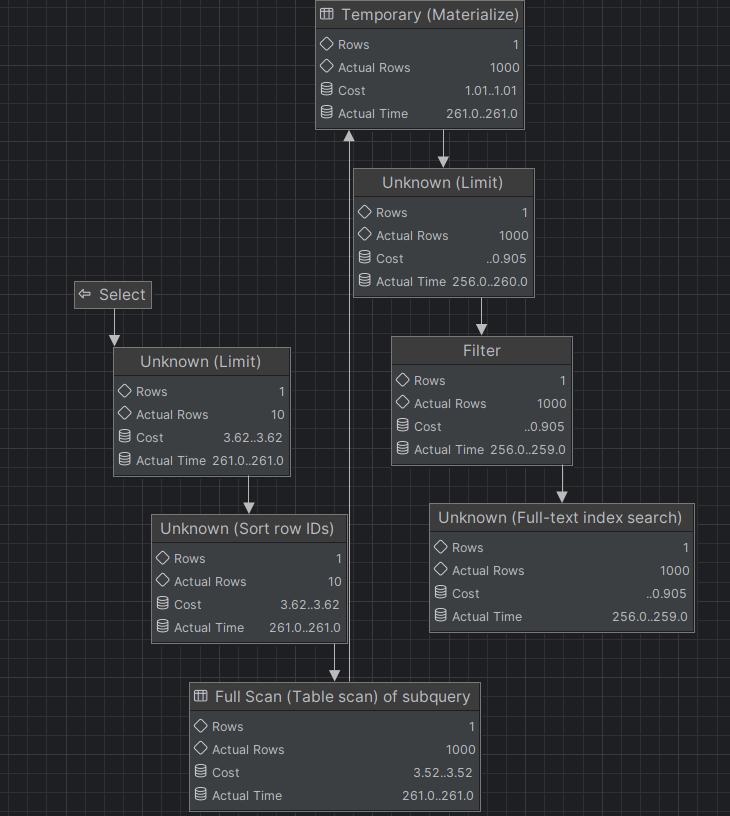
실제 책 이라는 단어로 100만개 이상의 검색결과가 나오는 검색어를 이용해도 응답 속도는 15초 -> 3초로 크게 줄어든 모습을 볼 수 있다.
더해 쿼리 실행 계획에서도 성능에 큰 영향을 끼치는 FullScan이나 NestedLoop가 발견되지 않는 모습을 발견할 수 있다.
그러나
FULLTEXT 인덱스의 활용, 비정규화 방식 채택, 정렬 최적화, 필요한 인덱스 생성의 방법을 적용해 큰 개선을 이뤘지만 하지만 3초도 여전히 아쉬운 속도이다.
실제 데이터가 방대하고, 검색이 정말 중요한 서비스의 같은 경우 ElasticSearch 같은 전문 검색 엔진을 도입한다고 한다.
우선 전문 검색 엔진의 도입은 배치 개선 이후 생각해볼 문제라고 생각이 들어 개선을 여기까지 하고 변경된 쿼리에 맞게 JPQL의 조정, 그리고 성능 테스트 및 쿼리 실행 계획 확인을 먼저 해보기로 했다.
최종 개선 및 결과
이 이상의 최적화는 전문 검색 엔진의 도입이 필요하다고 판단이 되어 우선 이 개선 버전에 대한 결과들을 정리해보려고 한다.
우선 최적화한 SQL에 맞게 애플리케이션 코드를 변경해야 한다.
JPQL 수정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
@Query(value = """
SELECT * FROM (
SELECT b.id AS bookId,
b.title AS bookTitle,
b.book_image AS bookImage,
b.search_text AS topicNames,
(MATCH(b.title) AGAINST (:keyword IN BOOLEAN MODE) * 3 +
MATCH(b.author) AGAINST (:keyword IN BOOLEAN MODE) * 2 +
MATCH(b.search_text) AGAINST (:keyword IN BOOLEAN MODE)) AS relevance_score
FROM book b
WHERE MATCH(b.search_text) AGAINST (:keyword IN BOOLEAN MODE)
ORDER BY MATCH(b.search_text) AGAINST (:keyword IN BOOLEAN MODE) DESC
LIMIT 1000
) AS subquery
ORDER BY relevance_score DESC
LIMIT :#{#pageable.pageSize} OFFSET :#{#pageable.offset}
""",
countQuery = """
SELECT COUNT(*) FROM book b
WHERE MATCH(b.search_text) AGAINST (:keyword IN BOOLEAN MODE)
""",
nativeQuery = true)
Page<Tuple> findBookListByKeyword(@Param("keyword") String keyword, Pageable pageable);
- nativeQuery를 사용한다.
- MATCH AGAINST는 MySQL 등 일부 DB에서만 지원하는 것이기 때문에 다른 DB까지 모두 고려하는 JPQL에서는 사용할 수 없다.
- 또한 서브쿼리를 활용해 정렬 최적화를 의도했다.
GROUP CONCAT 제거
search_text 컬럼은 JOIN을 피하고자 만들었는데 GROUP CONCAT 때문에 불필요한 JOIN이 발생해 search_text의 도입의 효과가 떨어졌었다. 따라서 search_text를 select하고 그 결과를 이용해 애플리케이션 코드 내에서 topic을 추출하는 방식으로 GROUP_CONCAT을 제거하고자 했다.
1
2
3
4
5
6
7
8
9
10
11
12
@Override
public Page<GetBookListResponseDto> getBookList(final String keyword, final Pageable pageable) {
List<String> validTopics = topicRepository.findAllTopicNames();
Set<String> topics = new HashSet<>(validTopics);
Page<Tuple> results = bookRepository.findBookListByKeyword(keyword, pageable);
return results.map(result -> {
List<String> topicNames = extractTopics(result.get("topicNames", String.class), topics);
return GetBookListResponseDto.create(result, topicNames);
});
}
이러한 방식으로 추출해 최종적으로 최적화한 SQL에 알맞게 서비스 코드를 수정했다.
최종 결과
쿼리 실행 계획은 각 개선 파트에 남겼기 때문에 Jmeter 테스트 위주로 정리해 어느정도의 개선이 있었는지 수치로 정리해본다.
Book 테이블의 데이터는 총 1,000,800개.
Book_Genre 테이블의 데이터는 총 1,999,823개.
검색어는 검색 결과가 수십개 정도인 ‘말’로 진행했다.
Jmeter 테스트는 users 250, seconds 5, loop count 20으로 진행했다.
버전 1 (Like)
- Jmeter 측정 불가.
- Postman 기준 API 1회 응답 시간 약 14분
버전 2 (일부 인덱스 추가 및 LOWER 제거)
- Jmeter 측정 불가.
- Postman 기준 API 1회 응답 시간 약 1분
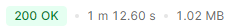
버전 3 (FULLTEXT INDEX 활용)
- Jmeter 측정 불가.
- Postman 기준 API 1회 응답 시간 약 1분 (성능 개선 거의 없음)
- 풀스캔 및 중첩 루프 조인 그대로 발생.
- 사실상 FULLTEXT INDEX가 제대로 적용되지 않음.
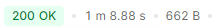
버전 4 (비정규화)
- Postman 기준 API 1회 응답 시간 54ms

- Jmeter 테스트
- avg: 0.659초
- min: 0.051초
- max: 2.594초
- 90% Line: 1.251초
- 평균적으로 에러도 없고 성능은 괜찮게 나오지만, 일부 요청에서 1초가 넘는 응답시간을 가져 추가적인 최적화가 필요하다.

주의 사항
비정규화를 통한 개선은 유의미하다. 하지만 검색을 위한 컬럼을 생성하는 것이기 때문에 만약 새로운 데이터가 생기거나, 데이터가 업데이트 된다면 search_text 컬럼 또한 업데이트가 되어야한다.
이는 어느정도 시간이 걸리고 비용이 드는 작업이기 때문에 스케줄러와 배치를 이용해 요청이 적은 시간대에 search_text 컬럼을 업데이트하는 작업을 따로 추가해주어야 한다는 단점이 존재한다.
버전 5 (조인 및 정렬 최적화)
- Postman 기준 API 1회 응답 시간 54ms

- Jmeter 테스트 (버전 4대비)
- avg: 0.369초 (44% 향상)
- min: 0.046초
- max: 1.519초 (41% 향상)
- 90% Line: 0.537초 (57% 향상)
- 대부분의 응답이 500ms 이내에 처리되는 것을 확인할 수 있다.
- 하지만 max 응답 시간에 문제가 있다.
- 캐싱을 적용해볼 수 있다. (상위 검색어, 인기 검색어 등)
![]()
- 캐싱을 적용해볼 수 있다. (상위 검색어, 인기 검색어 등)

성능이 크게 개선되었고 MySQL에서 개선할 수 있는 점은 쿼리 실행 계획 결과를 보면 거의 다 개선한 것 같지만 여전히 검색 결과가 수십만개일 경우 1~5초 사이의 응답시간을 보이기 때문에 문제가 있다.
이 부분은 전문 검색 엔진을 활용해야 될 것으로 보인다.
최종 비교 정리
| 버전 | 변경점 | Postman 응답 시간 | Jmeter 평균 응답 | 최대 응답 | 비고 |
|---|---|---|---|---|---|
| LIKE 사용 | 인덱스 활용 X | 14분 | 측정 불가 | 측정 불가 | 풀스캔, 중첩루프조인 |
| LIKE + 일부 인덱스 활용 | LOWER 제거 및 일부 인덱스 추가 | 1분 30초 | 측정 불가 | 측정 불가 | 동일 |
| FULLTEXT INDEX 적용 | FULLTEXT 인덱스 적용 | 1분 10초 | 측정 불가 | 측정 불가 | 큰 차이 없음, 여전히 풀 스캔 발생 |
| 비정규화 도입 | search_text컬럼 추가 | 0.054초 | 0.65초 | 2.59초 | 큰 성능 개선, 그러나 일부 요청에서 1초 이상 걸림 |
| 조인 및 정렬 최적화 | 서브쿼리 정렬 최적화 | 0.051초 | 0.36초 | 1.51초 | 약 40% 추가 개선, 대부분 0.5초 이내 응답 |
- 데이터를 100만개 이상으로 늘렸을 때 최초 버전의 응답시간 14분을 기준으로 최종 개선 버전에서는 0.054초로 99.99% 개선이 이루어졌음을 알 수 있다.
- 유의미한 개선 이후인 비정규화 도입 이후로 기준을 잡으면 0.65초 -> 0.36초로 약 44%의 성능 향상을 확인할 수 있었다.
추가 개선 방향
하지만 일부 키워드의 검색 결과가 많을 경우 여전히 응답시간이 길고, Jmeter 응답 max 수치도 1초가 넘어 아쉽다.
쿼리 실행 계획을 확인해보았을 때 MySQL 내에서 개선할 점은 거의 다 했다고 판단이 된다.
추가적인 개선 방향은 아래와 같이 정리해볼 수 있을 것 같다.
- 캐싱 적용
- 인기 검색어 및 자주 검색되는 검색어 캐싱
- 자주 조회되는 데이터 캐싱
- ElasticSearch 적용
- 검색 속도를 극대화할 수 있다.
- 분산 처리가 가능하다.
- 동의어, 오타 보정 등의 추가 기능을 가질 수 있다.
- MySQL 파티셔닝 적용
정리
현업에서는 ElasticSearch 같은 전문 검색 엔진을 도입하는 경우가 많다고 한다.
검색이 중점이 되는 서비스에서는 더더욱 그렇다고 한다.
검색 기능에 특화된 고급 기능과 분산 처리 능력 덕분에 대규모 데이터셋에서 빠른 응답 속도, 높은 검색 정확도를 제공할 수 있기 때문이다.
현재 이 개선 버전에서도 큰 개선은 있었지만, 데이터를 100만건을 삽입해놓아 특정 검색어의 검색 결과가 많을 시 응답속도가 n초가 걸리는 문제가 있다.
이를 해결하기 위해서는 전문 검색 엔진의 도입으로 개선을 해야될 것으로 보인다. 배치 개선 작업 후 ElasticSearch에 대해 공부해봐야겠다.