RDBMS와 NoSQL의 차이
관계형 데이터베이스 (RDBMS)
RDBMS는 행과 열을 가지는 표 형식의 데이터를 저장하는 형태의 데이터베이스를 가리킨다. SQL이라는 언어를 써서 조작한다.
MySQL, PostgreSQL, 오라클, SQL Server, MSSQL 등이 있다.
MySQL
대부분의 운영체제와 호환되며 현재 가장 많이 사용하는 데이터베이스이다
C, C++로 만들어졌으며 MyISAM 인덱스 압축 기술, B-트리 기반의 인덱스, 스레드 기반의 메모리 할당 시스템, 매우 빠른 조인, 최대 64개의 인덱스를 제공한다. 대용량 데이터베이스를 위해 설계되어 있고 롤백, 커밋, 이중 암호 지원 보안 등의 기능을 제공한다.
PostgreSQL
MySQL 다음으로 개발자들이 선호하는 데이터베이스 기술이다.
디스크 조각이 차지하는 영역을 회수할 수 있는 장치인 VACCUM이 특징이다. 최대 테이블의 크기는 32TB이며 SQL 뿐만 아니라 JSON을 이용해서 데이터에 접근할 수 있다. 지정 시간에 복구하는 기능, 로깅, 접근 제어, 중첩된 트랜잭션, 백업 등을 할 수 있다.
NoSQL 데이터베이스
NoSQL (Not Only SQL) 이라는 슬로건에서 생겨난 데이터베이스이다. SQL을 사용하지 않는 데이터베이스를 말하며 유연한 스키마, 확장성이 특징이다.
대표적으로 MongoDB와 Redis 등이 있다.
MongoDB
JSON을 통해 데이터에 접근할 수 있고, Binary JSON 형태 (BSON)로 데이터가 저장되며 와이어드타이거 엔진이 기본 스토리지 엔진으로 장착된 키-값 데이터 모델에서 확장된 도큐먼트 기반의 데이터베이스이다.
확장성이 뛰어나며 빅데이터를 저장할 때 성능이 좋고 고가용성과 샤딩, 레플리카셋을 지원한다.
또한 스키마를 정해놓지 않고 데이터를 삽입할 수 있기 때문에 다양한 도메인의 데이터베이스를 기반으로 분석하거나 로깅 등을 구현할 때 강점을 보인다.
MongoDB는 도큐먼트를 생성할 때마다 다른 컬렉션에서 중복된 값을 지니기 힘든 유니크한 값인 ObjectID가 생성된다. 이는 기본키로 유닉스 시간 기반의 타임스탬프, 랜덤값, 카운터로 이루어져 있다.
RDBMS와 NoSQL 데이터베이스의 차이 (MongoDB가 RDBMS와 차이를 보이는 점)
- key-value 형태의 도큐먼트
- MongoDB내의 도큐먼트는 key-value 형태로 이루어지며 _id라는 고유한 아이디를 가진다.
- DB에 저장될 때 key의 길이도 내용으로 들어간다.
- JSON 형태로 쿼리를 만들고 JSON을 매개변수로 받아 BSON 형태로 DB에 삽입, 추출하는 것이 가능하다.
- 그래서 type 변환이 일어나지 않으며 이를 통해 JSON 데이터를 주고 받을 때 성능 면에서 더 좋은 선택이 된다.
- 스키마 없이 삽입 가능하다.
- 스키마 없이 데이터 모델을 구현하지 않은 채 유동적으로 데이터를 삽입할 수 있다.
- 스키마란 데이터베이스를 구성하는 속성, 관계 등 데이터 값이 갖는 type을 명시해놓은 것을 말한다.
- 이를 통해 다양한 서비스로부터 데이터를 유동적으로 쌓을 수 있는 장점이 있다.
- 이에 따른 단점은 스키마를 미리 설정해두고 DB에 저장하는 RDBMS는 컬럼의 길이가 DB에 저장되지 않지만 MongoDB는 아니다.
- RDBMS의 경우 한 스키마가 int, char[14]인 경우 그 안에 들어가는 데이터인 18바이트만 저장된다.
- MongoDB는 한 도큐먼트로 칼럼이름도 바이트에 추가된다. key-value 형태이기 때문이다.
- ex) comments : string 이라면 comments 라는 길이의 byte가 더 들어가게 된다.
- 스키마 없이 데이터 모델을 구현하지 않은 채 유동적으로 데이터를 삽입할 수 있다.
- 데이터의 조합함수를 지원한다.
- MongoDB는 min, max, aggregate, mapReduce 등 강력한 함수로 데이터를 추출하고 조합해서 압축된 결과값을 만들어 낼 수 있다.
- 이중화 지원과 샤딩
- 서버는 멈추면 안되기 때문에 운영서버의 경우 서버 이중화를 한다.
- 이 때 MongoDB는 ReplicaSet을 이용해 이중화를 가능하게 한다.
- 또한 데이터의 양이 많은 경우 샤딩을 통해 collection을 분할해 관리할 수 있다.
- JSON 형태의 데이터
- MongoDB는 BSON형태로 저장되며 JSON 형태의 값으로 추출할 수 있다.
- JSON Object를 매개변수로 받아 쉽게 저장할수도 있다.
- 2차원 좌표 인덱싱
- geoSpartial 이라는 인덱스를 써서 2차원 좌표를 인덱싱할 수 있다.
- collection join
- $lookup을 통한 collection join이 가능하다.
- .B-tree를 적용한 인덱싱
- 인덱싱이 있어야 빠르게 데이터를 추출할 수 있다.
- 인덱스의 기본 정렬은 항상 오름차순으로 구현되지만 데이터를 추출할 때 또는 인덱스를 초기에 설정할 때는 변경할 수 있다.
- 인덱스는 B-tree로 구성되어 있다.
- 2차원 좌표 인덱싱의 경우 R-tree 이다.
Redis
인메모리 데이터베이스이자 키-값 데이터 모델 기반의 데이터베이스이다.
기본적인 데이터 타입은 문자열(string)dlau chleo 512MB까지 저장할 수 있다. 이외에도 set, hash 등을 지원한다.
pub/sub 기능을 통해 채팅 시스템을 구현하거나 다른 데이터베이스 앞단에 두어 사용하는 캐싱 계층, 단순한 키-값이 필요한 세션 정보 관리, 정렬된 셋(Sorted set) 자료구조를 이용한 실시간 순위표 서비스에 사용한다.
DB 스토리지 엔진
스토리지 엔진은 데이터베이스 관리 시스템이 데이터베이스에 대해 데이터를 삽입, 추출, 업데이트, 삭제 (CRUD)하는데 사용하는 기본 소프트웨어 컴포넌트이다.
innoDB, MyISAM (이상 MySQL), wiredtiger (MongoDB) 등이 있다.
(각각 변경 가능)
InnoDB와 MyISAM의 차이
InnoDB는 MySQL 8.0의 default 엔진이다. (MyISAM으로 변경 가능)
- InnoDB는 MyISAM에 비해 데이터베이스의 크기가 커졌을 때 더 큰 가용성을 제공한다.
- InnoDB는 행, 인덱스 조회 캐싱 기능이 있다.
- MyISAM은 파일 시스템 블록 캐시에 의존한다.
- InnoDB는 엔진 자체 내에서 행 캐시와 인덱스 캐시를 결합하여 작업을 수행한다.
- InnoDB는 행 수준 잠금을 사용한다.
- MyISAM은 테이블 수준의 잠금을 제공한다.
- MyISAM은 항상 테이블에 ROW COUNT를 가지고 있어 조회쿼리 시 빠르다.
- InnoDB는 트랜잭션 처리, 대용량 데이터를 다루기에 좋고 트린잭션이 필요 없고 조회기능이 많을 때 MyISAM이 좋다.
wiredtiger
MongoDB의 default엔진이다.
LSM Tree(로그 기반 병합트리)를 이용하여 읽기 성능을 포기하고 그만큼 저장 성능을 향상시켰다. 느린 읽기 성능을 보완하기 위해 블룸 필터를 사용한 엔진이다.
- 체크포인트
- MongoDB는 60초 간격으로 체크포인트를 생성한다.
- 체크포인트를 기반으로 복구할 수 있다.
- MongoDB가 종료되거나 새로운 체크포인트를 작성하는 동안 오류가 발생하더라도 다시 시작하면 MongoDB는 마지막 유효한 체크포인트에서 복구할 수 있다.
- 저널링
- 로그라고 부를 수 있는 저널링이 가능하다.
- 체크포인트 간의 모든 데이터 수정 사항을 유지한다.
- MongoDB가 체크포인트 사이에서 종료되면 저널을 사용해 마지막 체크포인트 이후 수정된 모든 데이터를 재생산 할 수 있다.
- 압축
- wiredtiger를 통해 모든 컬렉션 및 인덱스에 대한 압축을 지원한다.
- 메모리
- 약 50%의 메모리를 차지한다.
인덱스
인덱스는 데이터를 빠르게 찾을 수 있는 하나의 장치이다. 테이블 안의 내가 찾고자 하는 데이터를 빠르게 찾을 수 있도록 한다.
효율적인 이유?
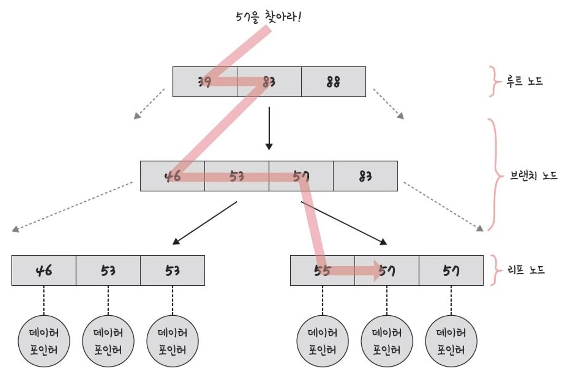
균형잡힌 B-Tree 기반으로 구축되어 있어 탐색에 평균 O(logN) 시간이 걸리며 트리 생성시의 대수확장성이란 특징으로 인해 더 빠른 시간안에 많은 데이터를 빠르게 찾을 수 있다.
B-Tree?
루트 노드, 리프 노드, 브랜치 노드로 이루어져 있으며 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리구조를 가진 균형잡힌 트리를 말한다.
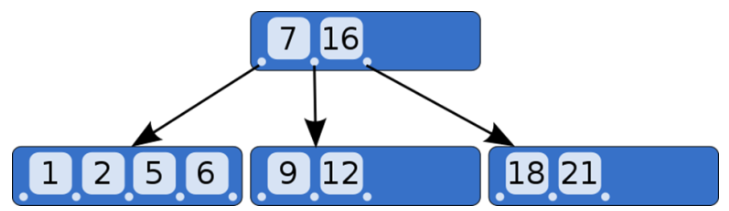
- 자식 노드의 개수가 2개 이상이고 노드 내의 데이터는 1개 이상이다.
- 데이터 수가 2개면 2차 B-Tree, 3개이면 3차 B-Tree..
- 노드의 데이터 수가 N개라면 자식 노드의 개수는 N+1개.
- 노드의 데이터는 반드시 정렬된 상태여야 한다.
- 자식 노드의 데이터들은 노드 데이터를 기준으로 데이터보다 작은 값은 왼쪽 서브 트리에, 큰 값들은 오른쪽 서브트리에 구성한다.
- 루트 노드를 제외한 모든 노드는 M/2개의 데이터를 보유한다.
- Leaf 노드는 모두 같은 레벨에 존재한다.
대수확장성?
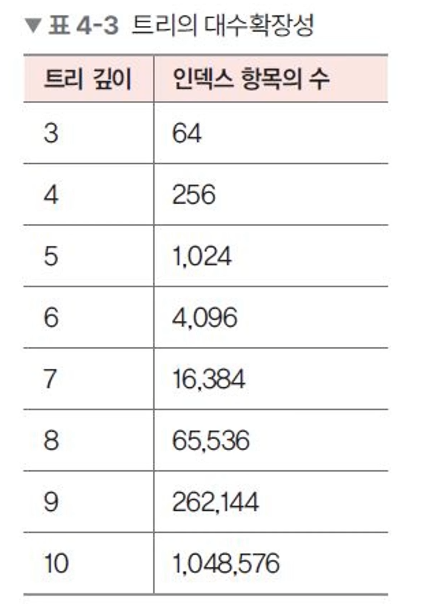
트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미한다. 깊이가 깊지 않으므로 탐색이 빠르다.
기본적으로 인덱스가 한 깊이씩 증가할 때 마다 최대 인덱스 항목의 수는 4배씩 증가한다.
인덱스의 최적화 기법
인덱스의 최적화 기법은 데이터베이스마다 조금씩 다르지만 기본적인 골조가 똑같기 떄문에 특정 DB를 기준으로 설명해도 무방하다.
아래 설명은 MongoDB의 인덱스 최적화 기법이다.
인덱스는 비용이다.
인덱스는 두 번 탐색하도록 강요한다. 인덱스 리스트, 그다음 컬렉션 순으로 탐색하기 때문에 관련 읽기 비용이 들게 된다.
또한 컬렉션이 수정되었을 때 인덱스도 수정되어야 한다. 마치 책의 본문이 수정되었을 때 목차를 수정해야 하는 것과 같은 느낌이다.
이 때 B-트리의 높이를 균형있게 조절하는 비용도 들고, 데이터를 효율적으로 조회할 수 있도록 분산시키는 비용도 들게 된다. 그렇기 때문에 쿼리에 있는 필드에 인덱스를 무작정 다 설정하는 것은 답이 아니다.
또한 컬렉션에서 가져와야 하는 양이 많을수록 인덱스를 사용하는 것은 비효율적이다.
항상 테스팅하라.
인덱스 최적화 기법은 서비스 특징에 따라 달라진다.
서비스에서 사용하는 객체의 깊이, 테이블의 양 등이 다르기 때문이다. 그렇기 때문에 항상 테스팅하는 것이 중요하다. explain() 함수를 통해 인덱스를 만들고 쿼리를 보낸 이후에 테스팅을 하며 걸리는 시간을 최소화해야 한다.
1
2
3
EXPLAIN
SELECT * FROM t1
JOIN t2 ON t1.c1 = t2.c1
위 코드는 MySQL의 테스팅 예시이다.
복합 인덱스는 같음, 정렬, 다중 값, 카디널리티 순이다.
보통 여러 필드를 기반으로 조회를 할 때 복합 인덱스(여러 컬럼을 묶어 인덱스 설정)를 생성하는데, 이 인덱스를 생성할 때는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다.
- 어떠한 값과 같음을 비교하는 ==이나 equal이라는 쿼리가 있다면 제일 먼저 인덱스로 설정한다.
- 정렬에 쓰는 필드라면 그다음 인덱스로 설정한다.
- 다중 값을 출력해야 하는 필드, 즉 쿼리 자체가 > 이거나 < 등 많은 값을 출력해야 하는 쿼리에 쓰는 필드라면 나중에 인덱스를 설정한다.
- 유니크한 값의 정도를 카디널리티라고 한다. 이 카디널리티가 높은 순서를 기반으로 인덱스를 생성해야 한다. 예를 들어 age와 email이 있다고 가정한다면 카디널리티는 email이 높다. 따라서 email이라는 필드에 대한 인덱스를 먼저 생성해야 한다.
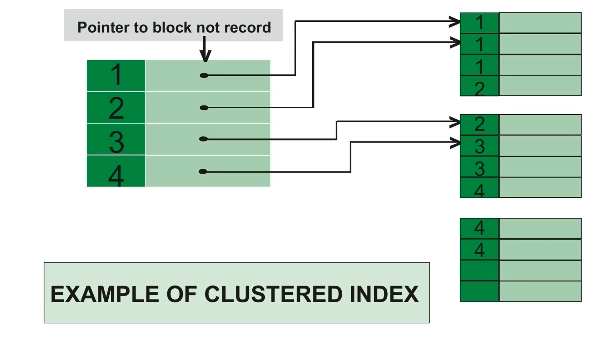
clustered Index, non-clustered Index
clustered Index
- 클러스터형 인덱스, 유일성과 최소성을 가지는 기본키 중 하나로 설정한다.
- 테이블당 한개. 보통 테이블의 기본키가 클러스터형 인덱스가 된다.
- 데이터페이지가 정렬되어 저장되며 인덱스 페이지의 리프노드에 데이터페이지가 들어가있다. 정렬되었기 때문에 탐색에 장점이있다.
- 데이터가 추가될 때마다 다시 모든 테이블을 정렬해야 하기 때문에 삽입, 삭제, 수정이 느리다.
- 테이블 레코드와 인덱스의 순서가 같게 조절된다.
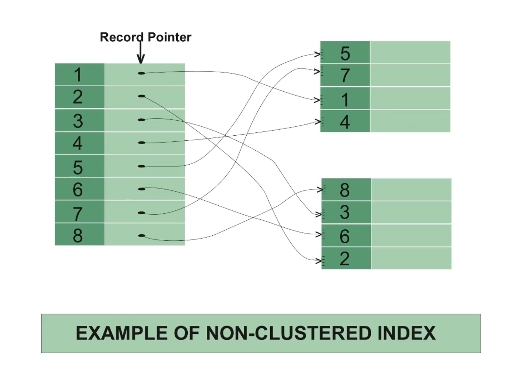
non-clustred Index
- 보조 인덱스라고 한다.
- 한 개가 아닌 여러 개를 만들 수 있다. 클러스터형키가 복합키가 될 수도 있긴하지만 보통 복합키를 만든다고 했을 때 보조 인덱스로 만든다.
- 클러스터형과는 달리 인덱스 페이지 리프노드에 실제 데이터가 있는 것이 아니라 데이터페이지에 관한 포인터가 있다.
- 정렬되어 있지 않아 탐색은 느리지만 삽입, 수정, 삭제가 빠르다.
- 인덱스의 순서와 데이터의 순서가 일치하지 않는다.