대규모 트래픽으로 인한 서버 과부화 해결 방법
서버 과부하?

서버가 리소스를 소진하여 들어오는 요청을 처리하지 못할 때 발생한다. 이 때 서버는 사용자의 웹 요청을 처리하지 못해 응답 없음을 보이게 된다.
어떤 주문의 할인 이벤트, 인기 있는 공연의 예매, 수강 신청 등등의 경우 발생할 수 있다.
모니터링을 통한 자원 할당
서버 과부화로 서버가 응답없음이 뜨는 것은 여러가지 이유가 있지만 그 중 하나는 바로 자원의 한계점 도달이다. 보통 서버의 CPU 사용량이 8~90%에 도달하거나 메모리가 부족해 계속해서 스와핑이 발생하면 과부화 상태가 된다.
- AWS 오토스케일링
- 서비스 이용 불가능 상태 발생 이전에 cloud watch가 지속적으로 모니터링 하여 서버 대수를 늘려주는 방법.
- 애플리케이션을 자동으로 모니터링하고 자원의 용량도 조정해준다.
- netdata를 이용한 모니터링
- AWS를 이용하지 않는 경우 활용할 수 있는 무료 모니터링 서비스
- 지속적인 모니터링, 이를 기반해 자원할당을 해주어 해결할 수 있다.
참고
이러한 모니터링 대시보드를 매번 볼 필요는 없고 slack 등과 연동해서 설정한 임계치를 기반으로 알림 서비스를 구축할 수 있다.
모니터링을 하는 이유?
서버과부화로 인해 서버 중지에 대한 대처를 하기 위함이다.
- 어떤 페이지에 어떤 트래픽이 얼마나 발생했느냐
- 어떤 네트워크에서 병목현상이 일어났나
- 이런 과부화를 대처하는 역할에 더해 모니터링을 통해 활용도가 낮은 페이지, 높은 페이지 등도 파악할 수 있어 서비스 개선에 도움이 된다.
로드밸런서
AWS 오토 스케일링은 빠르긴 하지만 구성에 시간이 걸리기 때문에 앞단에 로드밸런서를 통해 트래픽을 분산해야 한다.
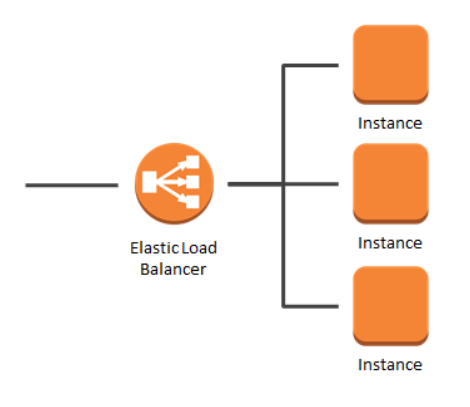
이렇게 트래픽을 분산시킨 것을 바탕으로 그 분산시킨 부분에 오토스케일링을 거는 것이다. 서버의 크기가 정말 크다면 로드밸런서에도 오토스케일링을 거는 경우도 있다.
블랙스완 프로토콜
블랙스완?
예측할 수 없는 사고가 일어난 것을 말한다. 사후에는 이 사고의 원인 등을 분석할 수 있지만 사전에는 이 사고를 예측할 수 없는 것을 말한다.
이러한 블랙스완은 매 번 일어나기 때문에 이에 따라 대비를 해야한다.
대표적으로 구글은 블랙스완이 발생하면 아래와 같은 수칙을 따른다. 서비스를 운영한다면 이러한 규칙을 정해놓는 것이 좋다.
- 영향을 받은 시스템과 각 시스템의 상대적 위험 수준을 확인
- 체계적으로 데이터를 수집하고 원인에 대한 가설을 수립한 뒤 이를 테스팅
- 잠재적으로 영향을 받을 수 있는 내부의 모든 팀에 연락
- 최대한 빨리 취약점에 영향을 받는 모든 시스템을 업데이트
- 복원계획을 포함한 우리의 대응 과정을 파트너와 고객 등 외부에 전달
서킷브레이커
서킷 브레이커 패턴이라고도 불리며 서비스 장애를 감지하고 연쇄적으로 생기는 에러를 방지하는 기법이다.
서비스와 서비스 사이에 서킷브레이커 계층을 두고 미리 설정해놓은 timeout 임계값에 도달하면 서킷브레이커가 그 이후의 추가 호출에 무조건 에러를 반환하는 방식이다.
이렇게 하면 서비스 A에 연결된 서비스 B나 C는 서비스 A에 에러가 발생했을 때 서비스 A를 기다리지 않고 에러가 났다는 사실을 알고 자원을 낭비하지 않아도 된다.
장점
- 연속적인 에러 발생을 막아준다.
- 일부 서비스가 종료되더라도 다른 서비스들은 이상 없이 동작하게 만들 수 있으며 사용자 경험을 높여준다.
참고
물론 응답을 기다리면 성공하는 경우도 있다. 하지만 오래기다리는 것은 좋은 UX가 아니다. 성공인지 실패인지보다 사용자가 기다리지 않는 것이 더 중요하다.
구현된 라이브러리
- 넷플릭스의 Hystrix
- Resilience4j
서킷 브레이커의 상태
- closed(정상) : 네트워크 요청의 실패율이 임계치보다 낮다.
- open(에러) : 임계치 이상의 상태를 말한다. 요청을 서비스로 전송하지 않고 바로 오류를 반환한다. 이를 fail fast 라고 한다.
- half_open(확인 중) : open 상태에서 일정 timeout으로 설정된 시간이 지나면 장애가 해결되었는지 확인하기 위해 half_open 상태로 전환된다.
- 여기서 요청을 전송하여 응답을 확인하고, 장애가 풀리는지를 확인해 성공하면 closed, 실패하면 다시 open으로 변경한다.
컨텐츠 관리
인프런의 이벤트 기간 장애 발생 (2022년 1월 3일 ~ 17일)
위의 링크에서는 인프런에서 장기간 서비스를 이용할 수 없는 큰 장애에 대해 정리한 글이다.
2022년을 맞이해 특정 강의를 100% 할인하는 이벤트를 진행한 것이다.
다양한 분야의 강의 125개, 총 500만원 상당의 강의를 무료로 제공한 것이다.
이는 트위터, 여러 IT 커뮤니티에 공유되어 평소 대비 5~20배의 트래픽이 발생했다고 한다. 이벤트는 성공이었지만 트래픽으로 인한 장애가 발생했다.
이 중 살펴볼 것은 1월 4일 장애에 대한 부분이다.
간단히 요약하면 DB에서 강의를 조회할 때 실제 사용하지 않는 부분도 같이 조회되어 자원을 낭비하고 있었던 것이다.
불필요한 컨텐츠 제거
위의 문제에서는 불필요한 쿼리등을 제거해 문제를 해결하였다. 이와 같이 불필요한 부분을 제거함으로써 서버 과부화를 해결할 수도 있다.
CDN을 통한 컨텐츠 제공
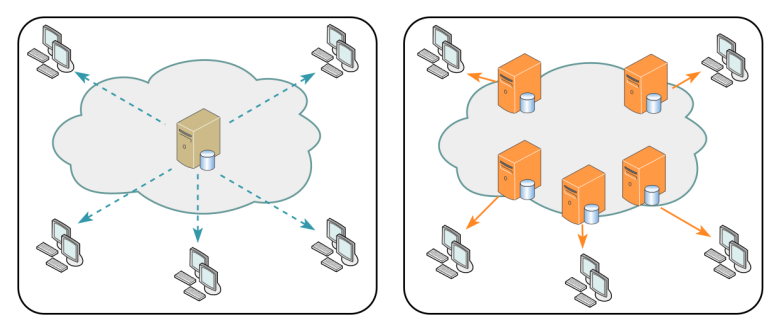
정적 자원같은 것을 메인서버에서 바로 줄 필요 없이 CDN을 통해 사용자 가까이, 그리고 분산된 대규모 서버 네트워크를 기반으로 컨텐츠를 제공해 메인 서버에 대한 부하를 줄이는 방법이다.
컨텐츠 캐싱
네트워크 트래픽 문제를 해결하는 가장 좋은 방법은 해당 트래픽이 발생하지 않도록 하는 것이다.
브라우저 캐시(쿠키, 로컬스토리지, 세션스토리지)를 통해 해당 요청에 관한 항목을 캐시에서 응답을 읽도록 하여 네트워크 요청에 관한 비용을 모두 제거한다.
컨텐츠 압축
텍스트 기반 리소스는 gzip 또는 Brotli를 통해 압축해야 한다. 압축하면 70% 정도 까지 압축할 수 있다. 다만 압축했기 때문에 압축을 풀기 위해 서버에서 자원(CPU)을 사용하는 양까지 고려해야 한다.
보통은 압축하면 더 나은 것을 보여준다.
컨텐츠의 우아한 저하(미리 준비된 응답)
시스템의 과도한 부하를 줄이기 위해 제공하는 컨텐츠 및 기능을 일시적으로 줄이는 전략이다.
예를 들어 정적 텍스트 페이지를 제공하거나, 검색을 비활성화하거나 더 적은 수의 검색 결과를 반환하거나 하는 등의 필수적이지 않은 기능을 일시적으로 비활성화 한다.
실제 사례 2023.05.31 서울시 경보 오발령 사태 - NHK WEB
NHK WEB에서는 필수적이지 않은 컨텐츠를 제외하고 경량화된 컨텐츠만 제공하였다. (이미지, 동영상 삭제 등)